I was 39, I was goal setting with my personal trainer and
said I would like to be able to do 40 press ups by my 40th birthday. He said
“sure, we can work towards that” which I now know is code for “good idea, but your
time scales are optimistic”.
I’m a big guy, well over 100kg, and had
nowhere near enough strength to do even a single press up. I'll be honest, I was
scared to try. In my imagination, attempting a press up would quickly result in me
face planting. It was a valid concern, even if the result would not be as comical
as I imagined, it most certainly would be a failed attempt. Work needed to be
done.
My PT wrote a plan, integrated it with my other goals and training
began. We started with barbell inclined press ups. This is where you stick a
barbell on a rack and do a press up at an inclined angle. It changes the
difficulty of the press up and helps you build up strength or change the focus of
the exercise or something. I'm a computer scientist not a sports scientist, but I
do know I could just about complete a set of ten.
At first the bar was very
high up the rack, I was practically standing, still the last couple of reps
especially of the last set were always tough. Over time, my PT would lower the
bar one notch and the difficulty would go up a level. Those were the weeks where
my PT would have to say “range” more often than normal, reminding me to do a full
rep, and in weeks where he started saying “good range” I knew the bar would move
down a notch next week.
We did other exercises too, some I'm sure part of a
plan to get me ready to do press ups, some for my other goals. All the time the
barbell slowly moving down the rack. It got lower and lower until one day, no bar,
just a mat on the floor and a grinning PT telling me “you've got this bro”. I
wanted to believe him but I wasn't convinced.
We started with knee press
ups, these are easier than normal press ups (got to love physics), but still more
challenging than the barbell ones.
The biggest thing preventing me from
doing a normal press up at this point was in my head, I now had the strength but
lacked confidence, I was still convinced an attempt would result in me face
planting into the ground. There was lots of time where I would stare at the mat.
From my PT’s point of view, I imagine it looked like I needed a reboot.
My
PT broke it down. We practiced lowering to the ground, the down part of a press
up. We practiced lifting off the ground, the up part. Eventually after many
false starts and much encouragement, I did attempt a normal press up. I did not
face plant. I surprised myself, so I did another one, and it was better. Then
fatigue genuinely kicked in and I completed the set with knee press ups. The next
week it was five normal and five from the knee. That kept improving until one day
I did a set of ten normal press ups. It wasn't long until I did four sets of ten
press ups. Some of them were scrappy but my PT said they counted, so four tens
are 40, goal achieved?
It didn't feel right. I never intended to do the 40
reps in one set, so four sets of ten is fine. But it felt hollow because I was
still not confident. The first rep of every set always felt like half a rep as I
tentatively tested I could lower down and come back up without falling. The last
few reps were such a struggle they didn't feel…clean. I did 40 press ups that
day, but it didn't feel good. I wasn't ready to declare victory just yet.
Training continued and I got stronger and more comfortable. A fifth set was
added and I continued to improve. The sets were extended to 12 reps, and my
confidence started to grow. Still that first rep was always a mess and I wasn't
ready to declare victory just yet.
Today was different though. Today I
started the first set and didn't think about it, I just got on with it. The first
rep was great, full range, strong, and I kept going. I was supposed to stop at 12
reps but found myself saying 15 shocked that I’d just done 15 press ups with no
issues. I had found my groove. I could have done more.
“Now you've done
it” said my PT. The next set I tried to stop after 12 but “nope, three more
please”, so I did. The third set was great, for the first time ever I felt like
there was a bit of spring in the movement, I wasn't constantly at the edge of my
ability, there was some room for acceleration. The fourth set was more of the
same, meaning I’d completed the 60 best press ups I’d ever done and I was ready to
declare victory.
I think my PT was more excited than me and he had an idea.
After a full recovery the fifth set was to be an AMRAP set, i.e as many reps as
possible, how many reps could I do? 15 was fine, 20 a breeze, after 25 I'm still
strong and aiming for 40, at rep 28 all my strength seems to run away, 30 was a
real struggle but I'll be damned if I'm stopping on 30, so I got one last rep. 31
full range, clean, awesome press ups in a single set. It might not be 40 but I
don't care, they felt great and for the first time I’m willing to say I can do a
press up. The count for the day is 91. Fantastic. Victory is mine!
I am
43 btw, so yer, timelines were a bit optimistic.
At its core the AES algorithm takes 128 bits of plain text and a secret key and encrypts the data into cipher text. This cipher text is an incomprehensible mess that is practically impossible to decipher unless you use the same secret key and the reverse AES algorithm to decrypt it.
AES uses various different methods to scramble the data. I'll explain each of these methods in turn but for now it's useful to know that these methods are used repeatedly in a loop and each time around that loop is called a round. I like to think of it like shuffling a deck of cards, you don't just shuffle once, you do it a number of times to make sure the deck is really messed up.
Another key property of AES is its heavy use of Galois Fields, especially GF(28). As a general rule, bytes are treated as vector arrays representing polynomials, and whenever addition or multiplication operations are performed, they are the operations from that field. This is why I spent so long learning about abstract algebra in preparation. I can’t overstate how much easier it is to understand AES if you have a good grasp of Galois Fields.
Enough preamble, let's get into the details.
S-boxes
One method AES uses to scramble data is a substitution box (s-box). This takes a number of input bits and replaces them with some number of output bits. This is typically implemented as a lookup table. AES uses an 8-bit to 8-bit s-box and can be implemented as a 256 element array, each element being an 8-bit value. Using the input as the index, the output is the element in the array at that index.
The creation of these s-boxes is tricky. It's important that no two input value maps to the same output. You don't want any value mapping to itself. Also it has to be nonlinear, which I translate to “unpredictable”, i.e. if you change one bit of the input you have no idea how many and which bits in the output will be affected.
Thankfully, we don't have to design the s-box, the authors of AES (Joan Daemen and Vincent Rijmen with some help from Kaisa Nyberg) already did that. And published it. We can just download the 256 values and paste them into our code, which would be perfectly acceptable and if that's what you want to do, go ahead. However they also published the process for generating the s-box and that seems like a lot more fun to me, so that's what I'm going to do.
The AES s-boxes use Galois Fields to do all the heavy lifting. The crux being the substitution value is the multiplicative inverse of the input value in GF(28) with the irreducible polynomial x8 + x4 + x3 + x + 1. As luck would have it, I already coded that in a previous post, here it is:
// Perform AES multiplication, i.e. polynomial multiplication in the field
// GF(256) with the irreducible polynomial x^8 + x^4 + x^3 + x + 1. Designed
// to work with 8 bit numbers despite the irreducible polynomial requiring 9
// bits.
static uint8_t aes_mul(uint8_t a, uint8_t b) {
uint8_t result = 0;
for (int i=0; i<8; i++) {
if (b & 0x01) {
result ^= a;
}
a = (a << 1) ^ (a & 0x80 ? 0x1b : 0);
b >>= 1;
}
return result;
}
// Perform polynomial division with 8 bit vectors.
static uint8_t poly_div(uint8_t a, uint8_t b, uint8_t* r) {
uint8_t mask = 0x80;
while (mask && !(mask & a) && !(mask & b)) {
mask >>= 1;
}
if (!(mask & a)) {
*r = a;
return 0;
}
uint8_t mag = 0;
while (mask && !(mask & b)) {
mask >>= 1;
mag++;
}
return (1 << mag) ^ poly_div(a ^ (b << mag), b, r);
}
// Perform polynomial division with the AES irreducible polynomial (which
// would normally require 9 bits) with an 8 bit vector.
static uint8_t aes_div(uint8_t b, uint8_t* r) {
uint8_t mask = 0x80;
uint8_t mag = 1;
while (mask && !(mask & b)) {
mask >>= 1;
mag++;
}
return (1 << mag) ^ poly_div(0x1b ^ (b << mag), b, r);
}
// Compute the AES multiplicative inverse using the Extended Euclidean Algorithm
static uint8_t aes_inverse(uint8_t r) {
uint8_t old_t = 0;
uint8_t t = 1;
uint8_t new_r;
uint8_t q = aes_div(r, &new_r);
while (new_r != 0) {
uint8_t new_t = old_t ^ aes_mul(q, t);
old_t = t;
t = new_t;
uint8_t old_r = r;
r = new_r;
q = poly_div(old_r, r, &new_r);
}
return t;
}
To further thwart cryptanalysis the multiplicative inverse is then transformed using the following affine transformation where b is the multiplicative inverse as a vector and s is the s-box output.
This is matrix multiplication, I have the code for that too. Well almost, because the vector (of 8 bits) is actually stored as an integer, we need to do some bit manipulation to read and set individual bits. Also, because these bits represent coefficients in a polynomial, the calculations are performed in GF(2) so addition becomes an XOR and multiplication becomes an AND.
// read a bit
bool rbit(uint8_t value, unsigned int bit) {
return (value >> (bit)) & 1;
}
// set a bit
uint8_t sbit(uint8_t value, unsigned int bit, bool set) {
const uint8_t mask = 1 << (bit);
if (set) {
return value | mask;
} else {
return value & ~mask;
}
}
static uint8_t affine_matrix[8][8] = {
{1, 0, 0, 0, 1, 1, 1, 1},
{1, 1, 0, 0, 0, 1, 1, 1},
{1, 1, 1, 0, 0, 0, 1, 1},
{1, 1, 1, 1, 0, 0, 0, 1},
{1, 1, 1, 1, 1, 0, 0, 0},
{0, 1, 1, 1, 1, 1, 0, 0},
{0, 0, 1, 1, 1, 1, 1, 0},
{0, 0, 0, 1, 1, 1, 1, 1}
};
static uint8_t affine_transform(uint8_t vector) {
uint8_t result = 0;
for (size_t h=0; h<8; h++) {
uint8_t bit = 0;
for (size_t w=0; w<8; w++) {
bit ^= affine_matrix[h][w] & rbit(vector, w);
}
result = sbit(result, h, bit);
}
return result ^ 0x63;
}
With that written we can now compute the s-box substitution for any particular byte.
Because zero has no multiplicative inverse, this is treated as a special case and given the value 99 (aka 63hex) which just so happens to be the only element not to appear anywhere else in the s-box.
But this is all terribly inefficient. The calculations involved, especially the division required for calculating the multiplicative inverse, are time consuming. It really would be better to use an array as a lookup table. So a compromise, I’ll compute the s-box values when the program first starts and store them in an array for later lookup. This way I'm not copying and pasting the table from Wikipedia, and I'm not needlessly computing the same expensive values over and over.
static uint8_t sbox[256] = {};
static void compute_sbox() {
sbox[0] = 0x63;
uint8_t value = 0;
do {
sbox[value] = affine_transform(aes_inverse(++value));
} while (value != 255);
}
This also allows me to dump the s-box table to the console so I can double check I did everything correctly. I present those results here, so you can copy and paste them if you like :P
63 7c 77 7b f2 6b 6f c5 30 01 67 2b fe d7 ab 76
ca 82 c9 7d fa 59 47 f0 ad d4 a2 af 9c a4 72 c0
b7 fd 93 26 36 3f f7 cc 34 a5 e5 f1 71 d8 31 15
04 c7 23 c3 18 96 05 9a 07 12 80 e2 eb 27 b2 75
09 83 2c 1a 1b 6e 5a a0 52 3b d6 b3 29 e3 2f 84
53 d1 00 ed 20 fc b1 5b 6a cb be 39 4a 4c 58 cf
d0 ef aa fb 43 4d 33 85 45 f9 02 7f 50 3c 9f a8
51 a3 40 8f 92 9d 38 f5 bc b6 da 21 10 ff f3 d2
cd 0c 13 ec 5f 97 44 17 c4 a7 7e 3d 64 5d 19 73
60 81 4f dc 22 2a 90 88 46 ee b8 14 de 5e 0b db
e0 32 3a 0a 49 06 24 5c c2 d3 ac 62 91 95 e4 79
e7 c8 37 6d 8d d5 4e a9 6c 56 f4 ea 65 7a ae 08
ba 78 25 2e 1c a6 b4 c6 e8 dd 74 1f 4b bd 8b 8a
70 3e b5 66 48 03 f6 0e 61 35 57 b9 86 c1 1d 9e
e1 f8 98 11 69 d9 8e 94 9b 1e 87 e9 ce 55 28 df
8c a1 89 0d bf e6 42 68 41 99 2d 0f b0 54 bb 16
While in software, like my web server, using a 256 byte array is the more efficient method, this is not always the case. In some implementations of AES there may not be 256 bytes of memory available to store the lookup. Examples include embedded systems or in hardware implementations. In these cases it may be preferable to compute the substitution on the fly as required.
Before moving on, the affine transformation can also be optimised, instead of performing a matrix multiplication you can use the sum of multiple circular shift operations of the input byte. Because the vector in this case is actually a byte, this is easier to code and quicker to execute.
I'm not 100% sure why the original matrix translates into those five rotations. My intuition says it's correct because the rows in the matrix consist of five 1s being circularly rotated, and while I tested it to make sure it generates the same results, I can't quite map it out in my head. No doubt this will bug me till I return to it and work out why, so maybe a future post on that.
Key expansion
AES supports three key sizes: 128, 192 or 256 bits. The key size dictates how many rounds the algorithm will perform, 10 for 128, 12 for 192 and 14 for 256. The add key operation is called once before the rounds start and once for each of the rounds. Each time the round key is 128 bits long, no matter the size of the initial key. With this information we can calculate how much key data we need. Also for reasons that will become clear in a minute, it's helpful to know this in multiples of 32-bit words instead of single bits.
Initial key size (bits)
Initial key size (32-bit words)
Rounds
Round keys
Key data (bits)
Key data (32-bit words)
128
4
10
11
1408
44
192
6
12
13
1664
52
256
8
14
15
1920
60
AES uses a key schedule to expand the initial key into enough data for all the round keys. This algorithm is almost as involved as the rest of the AES algorithm, it's kind of like an algorithm nested inside an algorithm.
The key schedule is repetitive, repeating the same steps until the required amount of key data is produced. Each repetition is also called a round, but it's important to note these key schedule rounds are not related to the rounds in the main AES algorithm. For example, with a 192-bit key, each round in the key schedule generates 192 bits of data. This requires a total of 8 rounds to generate all required data. However the main AES rounds consume the key data at 128 bits of data per round, requiring a total of 12 rounds after the extra initial key add.
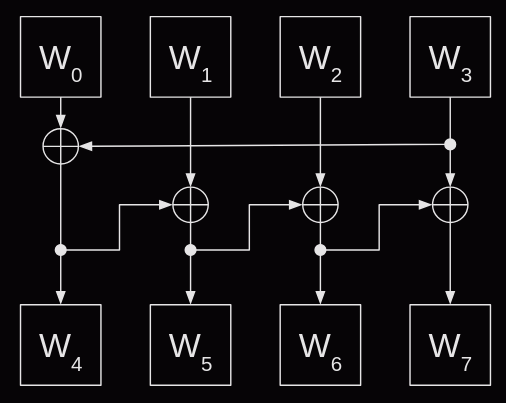
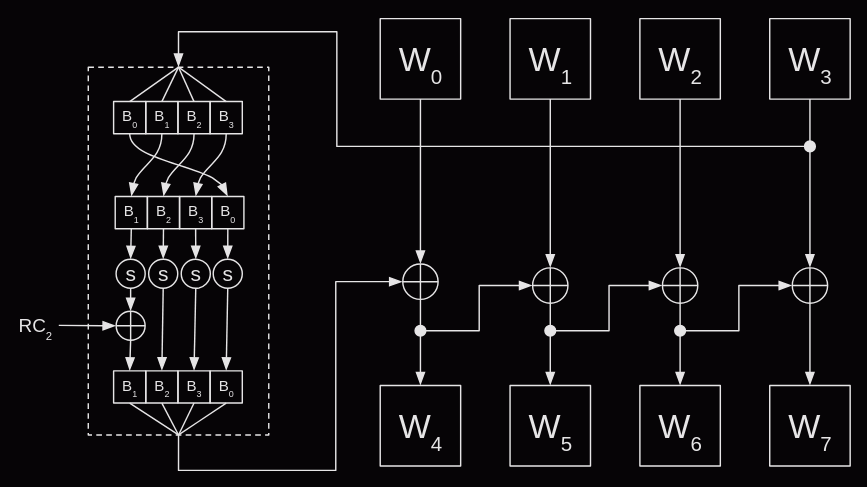
The algorithm is similar for all three key lengths, but for ease of explanation I shall start with the 128-bit key. The key schedule operates on 32-bit words, so for the 128-bit key there will initially be four 32-bit words and we need a total of 44 words. Each round of the key schedule generates four words, so a total of 11 rounds are needed.
The first round is simple, the first four words (w0 to w3) are a copy of the four words from the initial key. The subsequent rounds generate the next four words by adding the previous word (wi-1) to the word from the previous round (wi-4). This addition is performed in GF(232) so the addition translates into a bitwise XOR.
Except it's not quite that easy. The first word in each round actually goes through some extra transformations.
Take the previous word (wi-1).
Rotate the bytes in that word one to the left.
Apply the s-box substitution to each byte in that word.
Add a round constant to the high order byte. (More on this in a moment).
Add to the word from the previous round (wi-4).
The corrected diagram:
The round constant is a member of GF(23). It starts with the value 1 for the second round (it's not required for the first round which is a straight copy of the initial key). For each subsequent round it is multiplied by x. By round nine the round constant will be x7. For round ten, the multication by x will wrap around to x4 + x3 + x + 1. For reference this table gives the hex values for the round constant in each round.
The code is not quite as clean as I would like, this is mainly because some of the operations work on 32-bit words and some on 8-bit bytes. Storing the key as an array of 8-bit numbers as I’ve done above means some extra loops and some pointer arithmetic to convert from a word index to a byte index. Alternatively, storing the keys as an array of 32-bit numbers presents complications when wanting to manipulate a specific 8-bit byte for the s-box and round constant steps. In the end I went with the 8-bit route because the rest of the AES algorithm uses 8-bit bytes.
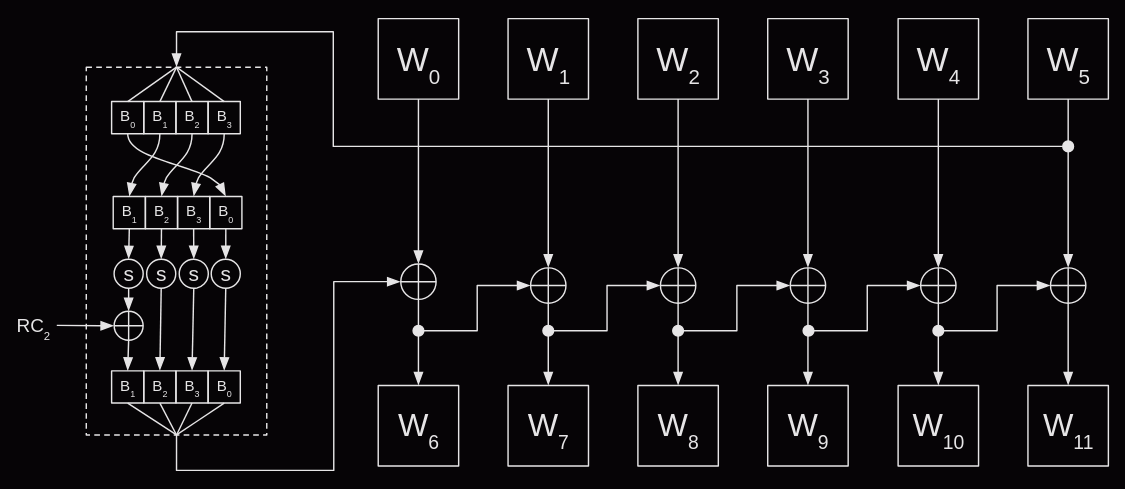
For a key length of 192, the algorithm is very similar. The initial key is six words long and we need a total of 52. This time, each round will generate six words. In general the round length will match the length of the initial key. As before the first round is a straight copy of the initial key. The first word in the subsequent rounds performs the more complex rotate-sub-add operations and the other five the simpler add operation.
The original code can be modified to work with both key sizes by replacing the hard coding with parameters defining the initial key length and total number of words required.
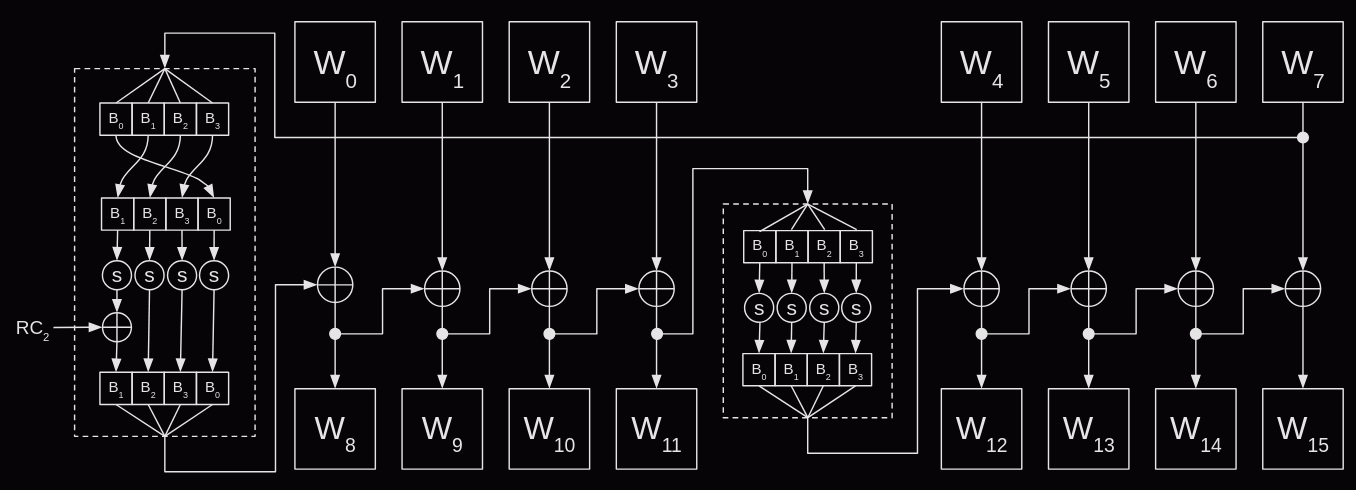
The algorithm for 256-bit keys is almost the same, the predictable difference being the algorithm now generates eight words per round. There is however an extra twist, the fifth word in each round is not a simple addition any more, instead the bytes of wi-1 are first substituted using the s-box.
This requires a minor update to the code, an extra branch to check for this condition and perform the extra substitutions.
With the s-box built and the key expanded, we are ready to start encrypting data.
Conceptually the data is divided into 16 (8-bit) bytes, and the 16 bytes are arranged in a four by four grid as shown below.
B0
B1
B2
B3
B4
B5
B6
B7
B8
B9
B10
B11
B12
B13
B14
B15
↓
B0
B4
B8
B12
B1
B5
B9
B13
B2
B6
B10
B14
B3
B7
B11
B15
The algorithm starts by adding the first 128-bits from the key schedule to the data. It then performs its main loop scrambling the data for a number of rounds depending on the key length. All the rounds are the same except the last one which skips a step for some reason. Here is the breakdown of all the steps performed:
Add round key
Each byte is combined with a byte from the first round key.
The next four steps are repeated for a number of rounds. The number of rounds depends on the size of the initial key. 9, 11 and 13 for 128, 192 and 256 bits respectively.
Sub bytes
Each byte is substituted with a byte from a lookup table.
Shift rows
The order of the bytes is modified by rotating the bytes in the rows.
Mix columns
The bytes in each column are mixed up using some matrix multiplication.
Add round key
The bytes are combined with the next round key.
One last round is completed, similar to the previous rounds but without the mix columns step
All the hard work for this step is already done. The key expansion has generated the round keys and the high level encryption function has selected the correct round key. All that is left to do is take the round key and add (XOR) it with the data.
Remember that the data in AES is conceptually arranged in a four by four grid of bytes. This step moves the bytes in each row about, technically it rotates them.
B0
B4
B8
B12
B1
B5
B9
B13
B2
B6
B10
B14
B3
B7
B11
B15
No change
Rotate 1 to the left
Rotate 2 to the left
Rotate 3 to the left
B0
B4
B8
B12
B5
B9
B13
B1
B10
B14
B2
B6
B15
B3
B7
B11
My instinct here was to use some kind of bit shifting to achieve this, but because the bytes in each row are spread out over the actual array of data (for example the second row consists of bytes 1, 5, 9 and 13) this would not work. I couldn't think of anything smarter than to just hard code the shift for each row.
This step performs matrix multiplication against each column, treating the column as a 4 element vector.
The code for this uses a variation of the matrix multiplication from the last post, the modification being the normal arithmetic is replaced with operations for GF(23). Additionally once the new vector (column) is computed it is written back over the original vector.
That's it, we are done, we can now encrypt data using AES.
Top secret text!→fa f5 82 c1 5e 19 d2 94 e7 22 7f fd 56 a4 dd af
Except we are not really done. For a start, we can only encrypt exactly 16 bytes (128 bits) of data. Conveniently my test string was 16 characters long, but what if we want to encrypt more? Or less? And how do we go about decrypting it?
Decryption
Let's start with decryption, that should be easy really, just do everything I've described so far backwards.
Well not quite everything is backwards. The key expansion is performed exactly the same as before, but the round keys are used in reverse order.
Sub bytes is reversed. To compute the reverse substitution we need to first perform the reverse affine transformation (the matrix multiplication below), then find the multiplicative inverse.
We need to take care with 63hex which after the reverse affine transformation will be zero which has no multiplicative inverse. Instead 63hex is substituted with 00hex. This should be no surprise as the forward s-box maps 00hex to 63hex.
There is however a cheat, we don’t need to compute the inverse s-box this way. When computing the normal forward s-box array, we can also populate the inverse s-box array by swapping the index and values.
The code for the reversed mix columns is basically the same. Each column is multiplied by a matrix. The only difference is the matrix being used, we now need to use the following inverse matrix.
Finally the algorithm as a whole performs the rounds and steps in the reverse order.
fa f5 82 c1 5e 19 d2 94 e7 22 7f fd 56 a4 dd af→Top secret text!
Modes of operation
Modes of operation are algorithms that wrap around AES to expand its use beyond the basic blocks of 128 bits. There are several modes of operation but for now I'm going to focus on two, ECB and CBC.
ECB or Electronic Code Book simply breaks the input data into 128-bit blocks and encodes each one in turn using AES. It's the obvious naive solution. It has problems cryptographically because the same message with the same key will produce the same cipher text. A duplicated 128-bit block in the message will also generate identical 128-bit cipher text. This opens this algorithm up to cryptanalysis.
ECB is also vulnerable to manipulation. While attackers may not be able to decipher blocks they could replace individual blocks undetected. If for example a bad actor works out that the second block of a message between banks describing a money transfer contains the destination account number, they could replace that block to redirect the transfer.
Granted, this analysis and manipulation requires a considerable effort and a little luck, but it's possible and can be avoided with a different mode of operation. The objective here is to first prevent two identical messages being encrypted into the same cipher text and thus prevent observers from spotting patterns and performing analysis. Second, prevent manipulation by allowing bad actors to replace blocks undetected.
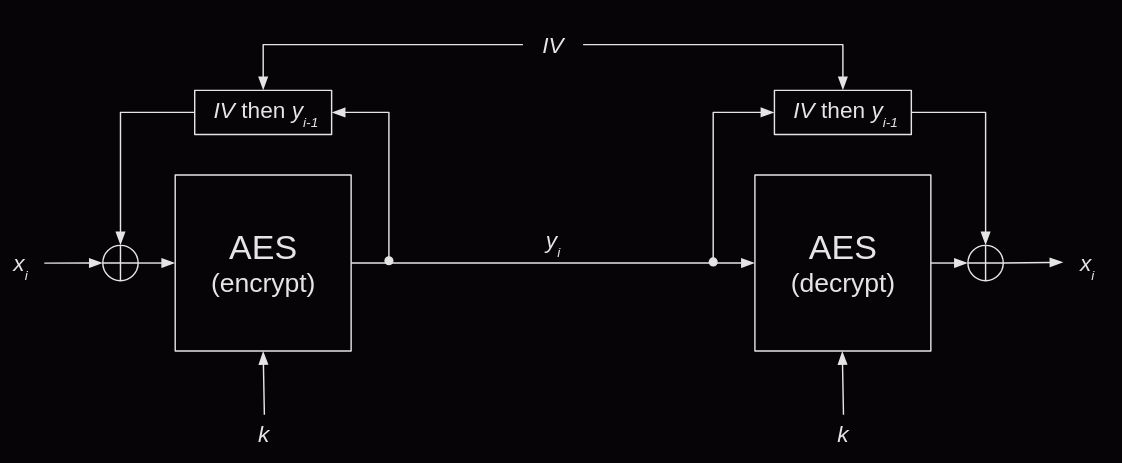
CBC or Cipher Block Chaining still breaks the input into 128-bit blocks but before encrypting each block the plain text is XORed with another block. For most of this algorithm the other block is the cipher text from the previous block, hence the Cipher Block Chaining name as each block is linked to the previous block. For the first block a random initial value is required, this is called the Initialisation Vector or IV. It is important that this IV is never used for more than one message. The random IV means duplicate messages will result in different cipher texts. The chaining means blocks cannot be replaced without corrupting the message.
When decrypting the message, the blocks need to be XORed after deciphering with the AES algorithm. The same IV needs to be used for the first block, and the cipher text of the previous block for all the others. Unlike the key, the IV does not need to be kept secret and can be transmitted in the clear.
Both these modes of operations rely on the data being an exact multiple of 16 bytes (aka 128 bits). This is obviously not the case most times. Everything being equal, 15 out of 16 times, the last block is going to be less than 16 bytes. This is where padding is required to fill out the last block.
There are multiple ways of doing this. The naive solution is to set the remaining bytes to 0 or a null byte. This encrypts fine but is difficult to decrypt as you can't be sure if the trailing byte is padding or a genuine null byte from the original plain text.
Another solution is to set the first padding byte to 80hex (10000000bin), and the remaining bytes to 0. This value, 80hex, is defined as the padding character in unicode. It is therefore easy to detect when decrypting if the source message was unicode encoded text. If it's ASCII it might work, if it's binary data we can't always be sure if it's a valid byte or padding.
Yet another solution is to pad to the remaining bytes with the number of padded bytes. For example if the last block has 11 bytes of data, the last 5 bytes are set to the value 5. When decrypting the last block, the last byte will be the number of bytes that can be removed as padding. If the message is an exact multiple of 16 bytes, there should be 0 padding but equally no where to store that value. In these circumstances, the message is instead padded with an extra block with all bytes being set to 16.
This method is called PKCS7 and seems to be the method most often used with ECB and CBC so is the method I've coded.
For testing I've wrapped all this code into a new executable called “crypto”. This is a basic command line tool that performs encryption and decryption using AES. The code beyond what has already been described above wrangles the command line parameters, handles IO and calls the appropriate AES encrypt or decrypt function.
I did this instead of trying to integrate it into Tinn because this is just a small part of TLS/HTTPS and trying to test this in isolation on a web server didn't make sense.
You can find a complete listing of crypto on github. If you decide to clone and build it for yourself, please don't trust it for anything real. While I'm confident it works, it has had no kind of actual review, it may well be leaking data all over the place.
Next
There are a bunch of optimisations I could make to this code. Chiefly I can combine a lot of the steps in each round into fewer operations. For example I could combine the sub bytes and shift rows steps into one and half the number of loops I need. Beyond this there are optimisations that can be made by processing each block as 4 32-bit words instead of 16 8-bit bytes. These changes make the code harder to follow, which is why I've not done it. It would make it faster and more efficient, but if that was my concern I should use a pre-existing library that has been optimised and tested by the wider community. I might visit these topics later, but for now I'm moving on.
AES is known as a symmetric encryption algorithm because it uses the same key for encryption and decryption. The big problem with AES and all symmetric encryption algorithms is key distribution. How do you get the secret key to the intended recipient without bad actors intercepting it and then having the ability to decipher all your secret messages? Well that's where asymmetric encryption algorithms come to the rescue and where I must journey next.
I’m almost ready to implement AES encryption. In truth, I've already done this, I've just not documented how. I was tempted to not to document it as part of this blog and instead write a more formal guide to TLS as a whole once I'd implemented everything and got HTTPS working. I still might take that approach going forward but I felt I should at least complete this series of posts on AES, just in case anyone was following along.
And I promise, in my next post I will finally get to the actual AES algorithm. First however, there is one last piece of mathematics I need to remind myself about, that is multiplying vectors with matrices.
A vector is something that contains multiple numbers as opposed to a scalar which is a single number. In geometry for example a vector is used to define a line which requires both a direction and a length. In computers we would typically use an array or tuple to store a vector. In modern programming a vector often refers to a specific type of data structure that implements a variable sized array. The computer version could certainly be used to store the mathematical version of a vector, but is not the only option, a normal fixed sized array is perfectly fine, preferable really. For the rest of this post, when I refer to a vector I mean the mathematical definition and not the data structure.
It seems to be convention to write vectors as a column of numbers in brackets, especially when doing maths with them.
A matrix is a 2D array of numbers. If you think of a vector as a column of numbers, a matrix is a rectangle.
To multiply a matrix by a vector, you take each number in a row from the matrix, and multiply those numbers by each number from the vector and add the results to get a number for a new vector. The simplest example of this is multiplying a one row matrix by a vector.
For matrices with multiple rows. You repeat the process for each row in the matrix to generate a new value in the resulting vector.
In general if the width of the matrix matches the height (size) of the vector, they can be multiplied and will result in a new vector with a height equal to the matrix.
That said, most of the time, especially when doing calculations with them, you will use a square matrix because the input and output vectors will be the same size. This leads us to the identity matrices that will return the exact same vector as given. This is a square matrix with the elements on the diagonal from top left to bottom right set to 1 and the other elements set to 0. Working through an example shows why this works.
Code
Unsurprisingly the code to perform this multiplication is basically nested loops.
void mxv(size_t width, size_t height, int matrix[height][width], int vector[width], int result[height]) {
for (size_t h=0; h<height; h++) {
result[h] = 0;
for (size_t w=0; w<width; w++) {
result[h] += matrix[h][w] * vector[w];
}
}
}
Not required for AES but for completeness you can also multiply two matrices together assuming the width of the first is equal to the height of the second. The progress is the same as with a vector but repeated for each column of the second vector with the result being a new square matrix.
In my last post, one area I skipped over was how to compute the multiplicative inverse in a finite field. For GF(7) I brute forced the answer for each element by testing each possibility. For GF(23) I had already calculated the result of every multiplication (mostly as an exercise) so I effectively brute forced that too.
In this post I'm going to explain how to use the Extended Euclidean Algorithm to do it more efficiently. I know that's the algorithm to use because multiple texts on the subject of cryptography said so. They didn't explain it further though, so I assume you are just supposed to know this stuff. I don't. So I best get studying.
Some time later
This is even older maths than abstract algebra. This comes from Euclid's Elements published in 300 BC. Euclid's Algorithm efficiently computes the greatest common divisor of two numbers. This is not what we want, but it helps and I'll explain why later, but first let's understand Euclid's Algorithm.
Take two numbers, for example 28 and 12, the greatest common divisor (GCD) is the biggest integer that divides into both numbers without leaving a reminder. You can work this out by factorising each number, comparing the two lists and selecting the biggest common number. The factors or divisors (it seems the terms are interchangeable) of 28 are 1, 2, 4, 7, 14 and 28. The divisors of 12 are 1, 2, 3, 4, 6 and 12. The largest common divisor is therefore 4. Or in maths speak .
This was possible to work out fairly quickly in my head. Turns out those times tables drummed into my head at school are still there decades later. But what if the numbers were bigger, say 973 and 301, I never learnt my times tables that high.
No worries, we can look them up. The divisors for 973 (1, 7, 139 and 973) and 301 (1, 7, 43 and 301) are listed on Wikipedia (https://en.wikipedia.org/wiki/Table_of_divisors). So . Using a list of precomputed divisors is not always practical, what if the numbers are really big, cryptography uses numbers 2000 bits long sometimes, what then?
This is also a tricky problem for computers. Factorising numbers is computationally expensive. It's slow. It's why people publish lists of them. Factorising is clearly not the solution.
Euclid's Algorithm provides an alternative method to work out the GCD without needing to factorise the numbers. It’s an iterative algorithm that starts by writing the larger value as a multiple of the smaller and working out the remainder. E.g.:
973 = q × 301 + r
In this case the quotient q is 3 as 301 goes into 973 3 times with a reminder r of 70.
973 = 3 × 301 + 70
The second iteration of the algorithm replaces the largest value with the smaller, and the smaller with the remainder from the previous iteration. Then repeat the previous step to work out a new quotient and remainder. In our example 70 goes into 301 4 times with a reminder of 21.
973 = 3 × 301 + 70
301 = 4 × 70 + 21
The algorithm keeps repeating this until the new remainder is 0.
The GCD is the previous remainder (or the last small value). In our example 7.
Let's test our first example too and make sure it computes the GSD(28, 12) as 4.
28 = 2 × 12 + 4
12 = 3 × 4 + 0
Well that was easier than factorising, even for small numbers. Nice.
To help turn this into code, and (spoilers) to understand the Extend Euclid Algorithm, it will help to label all the terms. The larger initial number is labelled r0, the smaller r1, its quotient is q1 and the new remainder is r2.
r0 = q1r1 + r2
The next iteration we move the terms about as previously described and calculate the new remainder.
r1 = q2r2 + r3
So in general each iteration is:
ri-2 = qi-1ri-1 + ri
The equivalent code is actually quite trivial. It's a simple recursive function. Recursion is magic.
int gcd(int a, int b) {
if (b == 0) return a;
return gcd(b, a % b);
}
So what is the extended version of the algorithm? Well, in addition to the GCD, it computes the coefficients of Bézout's identity. Clear? No. It's not for me either, so more research is required.
Research break.
Bézout's identity is a theorem that states for two integers (r0 and r1) with a common divisor, there exist integer coefficients (s and t) such that . This is going to be useful apparently, so let's push forward a bit longer and see how we can calculate s and t.
To understand the Extended Euclidean Algorithm we start by rearranging the equation at each stage of the original Euclidean Algorithm into the same signature as Bézout's identity.
Normal
Extended
973 = 3 × 301 + 70
1 × 973 + (-3) × 301 = 70
We don't completely simplify this equation. The final expression needs to be in terms of r0 and r1, in this example 973 and 301. We only simplify to the point we know how many r0 and r1 we need. In this first iteration we are already there so there is no further work required.
For the second iteration, the initial first term is a multiple of 301, which is r1, so nothing more needs to be done. The second term however is multiples of 70, which is not what we want. It is however the value of r2 and the previous iteration gave us an expression that represented 70 in terms of 973 and 301, or r2 in terms of r0 and r1. We can therefore substitute 70 and simplify the expression back to terms of r0 and r1.
The third iteration, the initial expression is in terms of 70 and 21, or r2 and r3. We already know we can substitute the 70 with the expression from the first iteration and the 21 can be substituted with the second expression.
The expression for the fourth iteration has a result of 0. We can therefore stop as we know the previous result, 7, is the GCD and the quotients in that expression are the values for s and t. Therefore s is -4 and t is 13.
If we did keep going and rearrange the result of the fourth interaction to be in terms of r0 and r1 we spot a pattern. The first term is multiples of 21 which was the result from 2 iterations above and the second term is multiples of 7, which was the result from the previous expression. For other longer examples it turns out this pattern holds true and therefore we can devise a generic expression to compute the new s and t values based on the previous two.
The burning question remains, what has this got to do with computing the multiplicative inverse? As a reminder, when an element in a field is paired with its inverse it results in the identity element. For multiplication the identity element is 1, so the multiplicative inverse is whatever element that when multiplied by the original result in 1. Or in maths speak:
a` × a = 1
Let's consider prime fields, specifically GF(7). This consists of the set of elements {0,1, …, 6}, and if we were to compute the GCD of each element with 7 the result would be 1. Because 7 is a prime, we can guarantee the GCD with positive integers smaller than it will be 1, that’s kind of the definition of prime numbers. We can then combine this with Bézout identity to assert that:
s×7 + t×a = GCD(7, a) = 1
In other words, there exists a quotient (s) for the prime 7 and a quotient (t) for any element (a) of the set where their sum will be 1.
Remembering that this is a finite field we can reduce the expression using modular arithmetic to ensure the result and all the terms are elements of the set. Specifically the first term s×7 is always going to result in a 0 as any multiple of 7 modulo 7 is 0.
s×7 ≡ 0 (mod 7)
So the first term will always reduce to 0 and can be cancelled out, the whole expression is then reduce to:
t×a ≡ 1 (mod 7)
This expression looks remarkably similar to our expression defining a multiplicative inverse, it is in fact the same signature. This makes t (mod 7) the multiplicative inverse of a. Which eventually answers the question we started with, how we can use the extended euclidean algorithm to compute the multiplicative inverse? Pipe in the modulus as r0 and the element as r1, the GCD will always be 1, s can be ignored and t will be the inverse.
int inverse(int a, int mod) {
struct eea_terms result = eea(mod, a);
return result.t<0 ? result.t+mod : result.t;
}
To test this works, I used the following script.
int max = 7;
for (int i=1; i<max; i++) {
struct eea_terms eear = eea(max, i);
printf("%d: r =%2d, s =%2d, t =%2d, inverse =%2d\n", i, eear.r, eear.s, eear.t, inverse(i, max));
}
Which generated this output
1: r = 1, s = 0, t = 1, inverse = 1
2: r = 1, s = 1, t =-3, inverse = 4
3: r = 1, s = 1, t =-2, inverse = 5
4: r = 1, s =-1, t = 2, inverse = 2
5: r = 1, s =-2, t = 3, inverse = 3
6: r = 1, s = 1, t =-1, inverse = 6
Excellent, job done, time to move on? Well not quite, we have those pesky polynomials to deal with.
The good news is it’s exactly the same process as with integers, we just need to make sure instead of calling the native addition, multiplication, division and modulo operators, we create and call functions that will perform correct operations with polynomials stored as bit arrays.
struct eea_terms gf2_eea_recurse(struct eea_terms i2, struct eea_terms i1) {
if (i1.r==0) return i2;
unsigned int r;
unsigned int q = gf2_div(i2.r, i1.r, &r);
return gf2_eea_recurse(i1, (struct eea_terms) {
.r = r,
.s = i2.s ^ gf2_mul(q, i1.s),
.t = i2.t ^ gf2_mul(q, i1.t)
});
}
struct eea_terms gf2_eea(unsigned int r0, unsigned int r1) {
return gf2_eea_recurse((struct eea_terms) {r0, 1, 0}, (struct eea_terms) {r1, 0, 1});
}
unsigned int gf2_inverse(unsigned int a, unsigned int mod) {
struct eea_terms result = gf2_eea(mod, a);
return result.t;
}
The tricky part was writing a division function, we got to skip this part in the last post as we took a shortcut when performing division, this time no such luck. The function works by looking for the position of the highest bit set in the dividend (a) and comparing that to the position of highest bit set in the divisor (b), the difference between them is the power of the first term in the result. Subtract this from the dividend and repeat recursively. It might sound complicated but it’s just long division in base 2. As a bonus, it also computes the remainder, in other words we can perform the division and modulo operation in one move.
unsigned int gf2_div(unsigned int a, unsigned int b, unsigned int* r) {
unsigned int mask = 1 << ((sizeof(unsigned int)*8) - 1);
while (mask && !(mask & a) && !(mask & b)) {
mask >>= 1;
}
if (!(mask & a)) {
*r = a;
return 0;
}
unsigned int mag = 0;
while (mask && !(mask & b)) {
mask >>= 1;
mag++;
}
return (1 << mag) ^ gf2_div(a ^ (b << mag), b, r);
}
With that now I can compute the multiplicative inverse for prime fields and extensions fields 2n. It's more than I strictly need to implement AES, but it's all useful learning. My math skills (for this tiny part of mathematics) are way more developed now than they have ever been. I really am having fun.
Guess what, I've not made much progress on implementing HTTPS. It's safe to say that it turned out to be very complicated, no surprise there.
I like to approach this kind of challenge by first getting a complete overview of the whole problem, then implementing it from the bottom up. To that end, I’ve read the tech specs and some books, I even watched some uni lectures I found on YouTube, and the good news is I now have a fairly good understanding of the steps required to implement an HTTPS server. I have actually learnt quite a bit, I’ve just not turned that into code yet.
As for the implementation, I decided to start with AES (Advanced Encryption Standard), which is the algorithm responsible for actually encrypting the data. It is just one of many acronyms I’m going to need to implement, but core to the whole process and something I can do in isolation from the rest of the process. There are few steps to the AES algorithm, called layers, which are essentially data manipulation and maths. This is good, I understand maths and can turn maths into code, write enough code and eventually I'll have an HTTPS server. The problem is I don’t understand the maths. It’s not normal maths.
One of the layers in AES calls for some multiplication, which shouldn't be an issue. I learnt how to multiply decades ago. One of the guides I was looking at helpfully showed an example:
00012 × 00112 = 00112
For those not fluent in binary this would typically look like this in your everyday decimal (aka normal numbers):
1 × 3 = 3
No problems so far but the second example flummoxed me:
Binary
Decimal
0011 × 0011 = 0101
3 × 3 = 5
Err, nooooo? When I was at school, 3 multiplied by 3 equaled 9. Didn't it?
The third example made sense again:
Binary
Decimal
0101 × 0011 = 1111
5 × 3 = 15
And then back to weird:
Binary
Decimal
1111 × 0011 = 1 0001
15 × 3 = 17
Do I actually understand maths?
One book I was reading, Implementing SSL/TLS by Joshua Davies, commented at one point “This probably doesn’t look much like multiplication to you, and honestly it isn’t”, it also pointed out that adding and multiplying in AES have been redefined to other operations/functions. It didn’t really explain why and just gave the code required to perform the operations, hinting it has something to do with finite fields. I think the book was written before “trust me bro” was a meme, but that is the vibe I was getting. There is nothing wrong with that approach, except I wanted to understand why.
I did some more research and found a collection of lectures Understanding Cryptography presented by Christof Paar and backed up by a textbook he co-authored. This did an excellent job of explaining what a finite field is and why 3 multiplied by 3 sometimes seems to equal 5. However it got a bit hand-wavey about how that would be implemented.
What didn’t help is that the code from the first book didn’t seem to bear any relevance to the theory I now understood from the second. What I needed was something that bridged the gap. To be fair that’s my responsibility, I can’t be expected to be spoon fed these things, this is what study is. So I did a lot of scribbling on scraps of paper and some serious staring at the ceiling whilst thinking about how basic maths really does work. The good news is that it eventually clicked!
I'm a big fan of the Feynman Technique which helps you learn something by pretending to teach it to someone else. This helps identify the holes in your understanding and makes sure you really do get it. If you can't explain it, you don't understand it. That's what a large part of this blog is, me learning stuff by explaining it. With that in mind, I present my primer on finite fields and how they apply to cryptography.
Sets
Finite fields belong to a branch of mathematics called Abstract Algebra. This is the study of sets and the operations you can perform on them.
A set is a collection of unique things. The things, called elements, can be anything but are normally numbers. Sets can have a finite number of elements, for example the decimal digits 0 to 9, or they can be infinite like the set of natural numbers. There are a bunch of rules and observations regarding sets and a whole sub branch of mathematics called set theory which we don't need to delve too deep into. We do however need to understand some of the notations used with sets.
You can define the elements of a set using words, the language can seem a bit formal but the intention is to be completely unambiguous.
"Let A be a set whose elements are the first five even natural numbers."
This is called a semantic definition. Or you can use a comma separated list between curly brackets to enumerate the elements.
A = {2, 4, 6, 8, 10}
For sets that have an obvious pattern you can use eclipses (...) as a shortcut. For example, a set of the first 100 natural numbers would be:
N = {1, 2, 3, 4, …, 100}
For infinite sets you can use the eclipse at the start or the end to show the set extends forever. For example, the set of integers would be:
Z = {..., -3 ,-2 ,-1 ,0 ,1, 2, 3, …}
Groups
Now we have sets we need to do stuff with the elements in them, what we need is operations. In general an operation is a function that takes as input elements from a set and outputs a result from the same set. A typical example is addition, it takes two elements, adds them together and returns the result.
An algebraic structure is when you combine a set with a number of operations and a number of conditions that the structure must meet. For example, a “group” is type of algebraic structure that consists of a set, an operation and meets the following rules:
The operation maps every pair of elements in the set to another element of the set.
The operation needs to be commutative.
The operation needs to be associative.
There is an identity element.
Every element has an inverse.
Let's consider the set {1, 2, 3, …, 8} with the operation addition and if this meets the criteria to be a group? Initially it seems ok, for example 2 + 3 = 5, however it's quickly evident there are pairs of inputs that when added together result in a number not in the set, for example 4 + 5 = 9. In fact over half the pairs of inputs result in numbers not in the set. Therefore we fail our first condition and can't consider this set with this operation a valid group.
To fix this we need more numbers, that's the thing with addition we always need a bigger number. The good thing is we can have infinite sets, we could instead use the set of natural numbers aka {1, 2, 3, …} which means no matter what pair of elements you pick, the result will also be in the set and meets the first of our criteria.
The second condition, that the operation must be commutative, is a fancy way of saying we can provide the elements to the operator in any order and get the same result. Addition meets this requirement. For example 2 + 3 and 3 + 2 both result in 5. In contrast subtraction is not commutative, 2 - 3 = -1 where 3 - 2 = 1.
The third condition, that the operation must be associative, means we can do repeated operations in any order and get the same result. Addition also meets this requirement. For example (2 + 3) + 4 = 9 and 2 + (3 + 4) = 9.
An identity element is something that can be paired with any other element and results in that other element. For addition, 0 is the identity element, add 0 to any other number and you get that number. The set of natural numbers does not include 0 and so combined with addition does not form a valid group. The set of whole numbers extends the natural numbers by adding 0, so switching to whole numbers means we can meet the first four criteria.
The inverse of addition is subtraction. If you add 3 to a number, to get back to that number you need to subtract 3. However we don’t have access to subtraction, only addition, but we can fake it by adding negative numbers. If you add 3 to a number, to get back to that number you need to add -3. Therefore the inverse of 3 is -3. The formal definition is when an element is paired with its inverse the result is the identity element, for example 3 + (-3) = 0.
The set of whole numbers contains no negatives so fails to meet criteria five and therefore fails to form a valid group with addition. To meet all criteria we need to switch to the set of integers which extends the whole numbers by adding all the negative numbers.
So the set of integers and addition form a valid group, which is kind of interesting but who cares? Well mathematicians care because groups help define how things like numbers actually work and from there they can make proofs from which they can build more complicated structures and do really smart things. You and I may take how numbers work for granted, but someone has to make sure they work how we think they do, and groups help mathematicians do that.
Computer scientists care because when they build a computer that they claim can do arithmetic, they want to be confident that the arithmetic will always work, or at least know how it is likely to break. As we just saw, for addition to work everytime we need an infinite set of integers. But computers can’t support an infinite number of integers, or even just one infinitely sized integer, at some point they will run out of memory, so computers have limits and groups help prove that.
As a result, when designing a computer or program to add numbers together you have to account for potential failures and report errors. If you've ever seen an overflow error on a computer or calculator, you've had first hand experience of this. Alternatively, if you really need your operation to succeed every time, if you need a valid group but can't use an infinite set, you can’t use addition and instead need a different operation.
Modular Arithmetic
Enter modular addition. Modular addition is where numbers wrap around to the beginning once they reach a certain value. The most familiar example of this is time and the 12 hour clock face. If the time is 10 o’clock and you add 4 hours, instead of the time now being 14 o’clock it is actually 2 o’clock because after the time reached 12 it wrapped back to 1.
Just like time and a clock, you can wrap around multiple times. Take 10, add 24 and you will wrap around 2 times and end up back at 10. In this modular system 10, 22, 34, 46, etc. are all equivalent to each other. Even -2 and -14 are equivalent to 10. It doesn't matter how far you go in either direction, every number will be equivalent to one of 12 numbers. This is essentially modular arithmetic.
Modular arithmetic allows the formation of a valid group with a finite set of numbers, in the clock example this is the set {1, 2, …, 12}. It passes the first rule as all pairs map to another element, wrapping round to 1 when required. It passes the second and third rules as the operation is commutative and associative. There is an identity element, which in this case is 12 because if you add 12 to any number you get back that number as it will wrap around once.
At first it might seem that elements don’t have an inverse because there are no negative numbers, if you add 3 how do you get back to where you started? The answer is to take advantage of the wrapping, if you add 3, to get back to where you started you need to add an additional 9. Looking at the formal definition, when an element is paired with its inverse the result is the identity element. The identity element is 12, so when you add 3 what do you need to add to get to 12? 9, it’s 9, we all knew that. A potentially tricky one is the inverse of 12, my intuition wants to say the inverse is 0 but because 0 is not part of the set we can’t use it and instead have to use 12, 12 is its own inverse.
A cleaner example would be to consider the 24 hour clock with midnight being the zeroth hour. The set would then be {0, 1, 2, …, 23} and the identity element would now be 0. The inverse of 3 would now be 21, the inverse of 10 would be 14 and the inverse of 0 would be 0. It’s the same idea but having 0 in the set means there’s less unnecessary wrapping around.
Starting at zero also allows us to consider modular arithmetic as the remainder from integer division. Take a number and divide that number by the modulus (the number of elements in the set) and the remainder will be congruent with the original number and one of the numbers in the set. For example, if the time now is 10:00 and you want to know what the time will be in 100 hours, first add 100 to 10 to get 110, then divide that by 24 but ignore the result (it’s 4 if you really needed to know) and instead take note of the remainder, which is 14, so the time will be 14:00 (or 2pm).
This operation of performing integer division but only returning the remainder is called the modulo operator, abbreviated to mod in mathematical notation:
110 mod 24 = 14
This is how I’m most familiar with using modular arithmetic, most programming languages have a modulo operator and so this is how I’m used to seeing it written down. However mathematical texts (and some books on cryptography) tend to use a different notation style that initially had me confused:
110 ≡ 14 (mod 24)
The triple line equals like symbol means equivalent and the (mod 24) in brackets applies to the whole expression not just the right hand side of the equivalent symbol. This expression should be read as “one hundred and ten is equivalent to fourteen in modulus twenty four”.
Back to computers. A typical 8 bit byte can be used to store a total of 256 numbers, it is fairly common to therefore use a byte to store the numbers from 0 to 255, i.e. the set {0, 1, 2, …, 255}. This is a finite set just like our clock example, so if we couple this with modular arithmetic which will wrap around should addition result in 256 or higher, we get a valid group and a system that avoids overflow errors. This is a common strategy in computer science. In a lot of places like the C programming language it’s actually the default behaviour. It’s not without pitfalls, especially for newer programmers who are not aware that they are not actually performing addition, they are performing modular addition. I’ve been using numbers like this for decades and so I’m very comfortable with it. I just never realised till now that I was using a group.
Fields
Fields, like groups, are an algebraic structure, but have two operations. Because there are two operations, it helps to give them names so they can be discussed and defined and those names are addition and multiplication. Crucially they don’t have to be the addition and multiplication we normally associate with numbers, but they do have to meet the rules listed below, so they will behave similarly to the addition and multiplication we are familiar with.
Both operations map every pair of elements in the set to another element of the set.
Both operations need to be commutative.
Both operations need to be associative.
There is an identity element for each operation, 0 for addition, 1 for multiplication.
Every element has an additive inverse.
Every element except 0 has a multiplicative inverse.
Multiplication distributes over addition.
As I did with groups, I want to first consider fields with normal addition and multiplication and what sets this will work with. We already know that a finite set, like {1, 2, …, 8}, will not work because addition fails with this set, but for the record, multiplication fails for the same reason, not all pairs map to an element. 3 x 4 for example results in 12 which is not part of the set. Using the infinite set of natural numbers, which fixes this for addition, will also fix this for multiplication.
Multiplication like addition is both commutative and associative. Which is handy
The identity elements have already been specified by rule four, 0 for addition and 1 for multiplication. We already know this works for addition and it only takes a moment’s thought to confirm any number multiplied by 1 is itself, so that checks out nicely.
We already know that to get the inverse elements for addition we have to expand to the set of integers so we have negative numbers, does this also help with multiplication? First, what is the inverse of multiplication? Well if I multiply a number by 2, to get it back to the original number I would have to divide it by 2 or half it, or put another way multiply it by the fraction ½. This pattern works for all numbers, the multiplicative inverse of a number is the fraction 1 over that number. For 3 it’s ⅓ for 10 it’s 1/10 etc. This means the set of integers is not going to work, our field requires fractions, we instead need to use the set of rational numbers.
There is no inverse for 0, because you can’t divide anything by 0, the fraction 1/0 does not exist. Recalling the formal definition of an inverse, when an element is paired with its inverse the result is the identity element. So what number multiplies with 0 to get 1? Well nothing, because every number multiplied by 0 is 0. Thankfully the elders of mathematics gave us an out for this one when writing the rules for a field, by not requiring a multiplicative inverse for 0.
The last requirement basically describes how addition and multiplication interact in a single equation. It asserts that a × (b + c) = (a × b) + (a × c). This is true for addition and multiplication, multiplying out the brackets was one of those exercises drummed into us at school, so we know it's true. But let's work through a trivial example to reassure ourselves it works:
With that we have a valid field, the most noteworthy part being we had to switch from the set of integers to the set of rational numbers to meet the multiplicative inverse requirement. I’ve always known that division was a pain in the butt.
Prime Fields
Back to computers again, and we can’t use the infinite set of rational numbers to support multiplication, but can modular arithmetic help out? Let’s take a look. Modular arithmetic works much the same with multiplication as it does for addition, if the number gets too big it wraps back around to the beginning. Let’s consider the set of the first 8 whole numbers aka {0, 1, …, 7}. 2 × 3 = 6, no problem there, 3 × 4 = 12 ≡ 4 (mod 8), also valid. It’s fairly easy to see that this meets all the requirements for a field except for the multiplicative inverse, which needs some more thought.
We can’t use fractions for the inverse as they are not in set. But maybe as with addition we can use the wrap-around properties of modular arithmetic to find an inverse. There are only eight elements in the set let's check them all. We can skip 0 because the rules let us. 1 is also easy because 1 is it’s own inverse, 1 × 1 = 1 and 1 is the identity element. 2 is the first problem, the plan is to keep multiplying it by each element in the hope that one of them will wrap around to the identity element (i.e. 1). 2 × 1 = 2, well we knew that but had to start somewhere, 2 × 2 = 4, no good, 2 × 3 = 6, still no good, 2 x 4 = 8 ≡ 0 (mod 8), it wrapped around but not to 1, 2 × 5 = 10 ≡ 2 (mod 8), ah, we are back to where we started, jumping over the identity element. It’s easy to see that this pattern would continue, and there is no element that would result in 1. Therefore this set and modular arithmetic do not form a valid field.
It does however hint at a possible solution, what if the set had an odd number of elements, then when we wrapped around we should at some point land on 1. Let's try a set of seven elements, {0, 1, …, 6}. The inverse for 0 and 1 work the same as last time. 2 initially works the same, but 2 × 4 = 8 ≡ 1 (mod 7), success! What about the other elements? Turns out all of them have a pair that results in the identity element aka an inverse.
As a result a set with the first seven whole numbers and modular arithmetic forms a valid field. This is known as a finite field of order seven, in notation this is written as GF(7). GF stands for Galois Field, another name for a finite field, named after Évariste Galois a French mathematician who did a lot of the groundwork that became abstract algebra.
It turns out that all sets with a prime number of elements form a valid finite field with modular arithmetic. It wasn’t a coincidence that I picked a set of seven elements for my example. These fields are also referred to as prime fields. They all work as our example, the elements of the set are the integers from 0 to p-1 where p is a prime number and the operations are addition and multiplication modulo p.
Extension Fields
The problem we face in computing and specifically in cryptography, we want to use sets that are not a prime number of elements, for example encryption wants a set that is 256 elements in size.
The good news is mathematicians like Galois worked out that for sets with pn elements, where p is a prime number and n is a positive integer, there exists a valid finite field. For the prime fields n will be 1. Fields where n is greater than 1 are called extension fields. More good news is 2 is a prime number and 28 is equal to 256 so we should be able to have a valid finite field with 256 elements.
But first a smaller example, 23 = 8, so there should also be a valid finite field with eight elements but we already tried that and it failed. The trick to extension fields, is the elements are not numbers, they are polynomials.
Polynomials
A polynomial is an expression consisting of the sum of many terms. A term consists of a coefficient and a number of variables raised to a power. It would be easier to explain with an example:
3x2 + 7x - 6
This polynomial has three terms, 3x2, 11x and -6. The coefficient for the first term is 3, the second 7 and the third -6. This polynomial has only one variable, x. In the first term it’s raised to the power 2, so this would be called a 2nd degree term. In the second there is no power written down, but technically this is raised to power 1, and would be called a 1st degree term. In the third term there is no variable listed, but this could be written as x0, which always evaluates to 1 and why it’s not normally shown. This third term could be called a zero degree term, but is normally called the constant term. It’s not normal but perfectly valid to write this polynomial like this:
3x2 + 7x1 - 6x0
The finite field with eight elements, aka GF(8) or GF(23), consists of the elements {0, 1, x, x + 1, x2, x2 + 1, x2 + x, x2 + x + 1}. It might be hard to spot the pattern at first, but maybe this table will help clear things up.
Normal
Expanded
x2
x1
x0
0
0x2 + 0x1 + 0x0
0
0
0
1
0x2 + 0x1 + 1x0
0
0
1
x
0x2 + 1x1 + 0x0
0
1
0
x + 1
0x2 + 1x1 + 1x0
0
1
1
x2
1x2 + 0x1 + 0x0
1
0
0
x2 + 1
1x2 + 0x1 + 1x0
1
0
1
x2 + x
1x2 + 1x1 + 0x0
1
1
0
x2 + x + 1
1x2 + 1x1 + 1x0
1
1
1
The coefficients of these elements can be one of two values, 0 or 1. There are two possible values because the prime number in this field is 2. Each element has three terms. There are three terms because the prime number in this field is raised to the power of 3. The elements in this polynomial are formed from all the possible combinations of coefficients over all three terms.
For those familiar with binary, you might have spotted that the coefficients count up in a binary sequence. More on this later.
As a quick aside, the finite field with nine elements aka GF(32) would have three possible values for the coefficient and two terms.
Normal
Expanded
0
0x1 + 0x0
1
0x1 + 1x0
2
0x1 + 2x0
x
1x1 + 0x0
x + 1
1x1 + 1x0
x + 2
1x1 + 2x0
2x
2x1 + 0x0
2x + 1
2x1 + 1x0
2x + 2
2x1 + 2x0
In general the elements of a extension field GF(pn) will consists of pn polynomials, each with up to n terms and each term with have coefficients from the field GF(p).
Addition in GF(2n)
If we are going to form a field with a set of polynomials, we are going to have to remind ourselves how to add and multiply polynomials together. Let's start with addition. This is the relatively simple process of grouping terms together that are raised to the same power and adding their coefficients together. For example:
(3x2 + 7x - 6) + (x2 + 3x + 2) = 4x2 + 10x - 4
In this example the 3x2 is added to the x2 to make 4x2, the 7x is added to the 3x to make 10x, finally the -6 is added to the 2 to make -4. Simple.
Addition in extension fields this works much the same, except the coefficients are from prime fields and so the simple addition is replaced with modular addition. For example in GF(23) if we where to add x + 1 to x we don’t get 2x + 1 as you might expect because 2 is not part of the set {0, 1} and instead wraps round to 0 so you actually get 0x + 1 or simply 1.
(x + 1) + x = 2x + 1
≡ 0x + 1
≡ 1
At first this seems very alien if you are still applying value to these “numbers”, how can you add two numbers together and get less? That is the mental gymnastics you need to perform, these are not numbers, they are just elements in a set and addition, despite its name, is just a function that allows you to combine two elements of the set to get a third in a predictable and repeatable way.
Here is a table that shows the results of addition for all possible pairs in a finite field of order eight.
Addition in GF(23)
0
1
x
x + 1
x2
x2 + 1
x2 + x
x2 + x + 1
0
0
1
x
x + 1
x2
x2 + 1
x2 + x
x2 + x + 1
1
1
0
x + 1
x
x2 + 1
x2
x2 + x + 1
x2 + x
x
x
x + 1
0
1
x2 + x
x2 + x + 1
x2
x2 + 1
x + 1
x + 1
x
1
0
x2 + x + 1
x2 + x
x2 + 1
x2
x2
x2
x2 + 1
x2 + x
x2 + x + 1
0
1
x
x + 1
x2 + 1
x2 + 1
x2
x2 + x + 1
x2 + x
1
0
x + 1
x
x2 + x
x2 + x
x2 + x + 1
x2
x2 + 1
x
x + 1
0
1
x2 + x + 1
x2 + x + 1
x2 + x
x2 + 1
x2
x + 1
x
1
0
The additive inverse, aka subtraction, works much the same way with our other groups and fields with modular arithmetic. What do we need to add to each element to get back to the identity element (which is 0)? Considering each term separately, we can take advantage of the wrap around effect of the coefficients to zero them out.
A neat side effect of GF(2n) fields is every element is its own inverse. This is because the coefficients can only have the value 0 or 1 and adding 1 to 1 wraps back round to 0. Adding 0 to 0 also gives 0, which was hopefully obvious. The point is adding a coefficient to itself will always result in 0. The effect of this can be seen in the table above, the diagonal from top left to bottom right always results in 0.
This is also why texts on AES encryption will often describe addition and subtraction as the same thing. It's because adding elements and subtracting elements has the same result. What they don't always explain is this is because of the nature of GF(2n) fields.
Multiplication in GF(2n)
Let’s remind ourselves how multiplication works with polynomials. We take each term in one polynomial and multiply it by each of the terms in the other, then add the results together. To multiply each term, we add the powers and multiply the coefficients. For example:
3x2 × 4x = 12x3
A complete example:
This works similarly in our extension field:
x(x + 1) = x2 + x
The question is what happens when the multiplication results in something that is not in the set, for example:
(x + 1)(x2 + x) = x3 + 2x2 + x
First, like with addition the coefficient in the 2x2 term will wrap around to 0, essentially removing that term. The remaining x3 + x is still not in our set, and again the answer is to use modular arithmetic, divide this by the modulus and take the remainder.
In our previous examples with natural numbers the modulus was in general the number of elements in the set, the polynomial equivalent is to use an irreducible polynomial of order one higher than supported by the set. In other words our set has terms raised up to the power of two (x2) so we need a polynomial with an term of power three (x3).
Irreducible in this context means the polynomial can not be factored, a bit like a prime number. It seems like there is no easy way to find an irreducible polynomial, every thing I've read on the subject seems to brute force it by testing each possible polynomial of that order to see if it can be factored. Also there is often more than one possibility, so when the field is defined (like in cryptography) it’s documented which polynomial to use as a modulus.
For GF(23) we can use the irreducible polynomial x3 + x + 1. Which means I now need to divide a polynomial…I don’t think I ever did that at school, or I have at least purged it from my memory. It turns out you use a long division method very similar to the long division I do remember from school. Basically sort the two polynomials with the high order terms first, then divide the first term in the dividend by the first term in the divisor, multiply the divisor by that result and subtract it from the dividend to get a new polynomial and repeat. Our example looks like this.
We only had to do one iteration, the result was 1 (which we don’t care about) and the remainder is 1, which is the answer we are looking for. And so in GF(23) the result of multiplying x + 1 with x2 + x is 1.
Here is a more complicated example which is the result of multiplying x2 with x2 + x.
In this instance we had to do two iterations, the result being x + 1 (which we can discard) and the remainder is x2 + 1 which is the answer we are looking for.
The following table shows all the results of multiplication in a finite field of order eight using x3 + x + 1 as the modulus.
Multiplication in GF(23)
0
1
x
x + 1
x2
x2 + 1
x2 + x
x2 + x + 1
0
0
0
0
0
0
0
0
0
1
0
1
x
x + 1
x2
x2 + 1
x2 + x
x2 + x + 1
x
0
x
x2
x2 + x
x + 1
1
x2 + x + 1
x2 + 1
x + 1
0
x + 1
x2 + x
x2 + 1
x2 + x + 1
x2
1
x
x2
0
x2
x + 1
x2 + x + 1
x2 + x
x
x2 + 1
1
x2 + 1
0
x2 + 1
1
x2
x
x2 + x + 1
x + 1
x2 + x
x2 + x
0
x2 + x
x2 + x + 1
1
x2 + 1
x + 1
x
x2
x2 + x + 1
0
x2 + x + 1
x2 + 1
x
1
x2 + x
x2
x + 1
Now we need to know what the multiplicative inverse for each element in the set is (except for 0). In other words what element should we multiply something by to get back to the identity element of 1. We could cheat and just use the table above, handley each row has a result equal to 1 in it, and that indicates the inverse.
Element
Multiplicative Inverse
1
1
x
x2 + 1
x + 1
x2 + x
x2
x2 + x + 1
x2 + 1
x
x2 + x
x + 1
x2 + x + 1
x2
But thinking forwards, that’s not going to scale to when I have 256 elements, there must be a way to compute it? There is, it’s called the Extended Euclidean Algorithm and that will be a future blog post because I need to start bringing this post to a close.
Representing Polynomials
At this point we have a field with 23 aka eight elements and it meets all of our criteria to be a valid field. We can scale this up to 28 or 256 elements by using polynomials up to the 7th degree (x7). All the maths is the same, just with more terms. The next thing to understand is how we would store polynomials in a computer and how we perform these operations on them.
I pointed out earlier that the coefficients for each term can have the value 0 or 1, and if you consider the coefficients in isolation they count up in a binary sequence. This hints as to how we can represent these 2n polynomials in a computer, we use a bit array to represent the coefficients.
Element
Bit array
0
0000 0000
1
0000 0001
x
0000 0010
x + 1
0000 0011
x2
0000 0100
x2 + 1
0000 0101
x2 + x
0000 0110
x2 + x + 1
0000 0111
…
…
x7 + x6 + x5 + x4 + x3 + x2 + 1
1111 1101
x7 + x6 + x5 + x4 + x3 + x2 + x
1111 1110
x7 + x6 + x5 + x4 + x3 + x2 + x + 1
1111 1111
For GF(28) we need 8 bits, and therefore can be stored in a single byte. In code, this is done using normal unsigned 8 bit integers. The key is to remember they are not normal numbers and you can’t use the normal addition and multiplication operators on them and get the results we want.
It is at this point we can eventually address my initial confusion as to why numbers seemingly did not add up. Let’s work though the first example again:
00012 × 00112 = 00112
We start with two bit arrays
0001 × 0011
Translate this to polynomials
1 × (x + 1)
Compute the result
x + 1
Convert back to a bit array
0011
That works as expected, and it is completely coincidental that the result is also the same if you do normal binary multiplication. Let's look at the second example:
00112 × 00112 = 01012
We start with two bit arrays
0011 × 0011
Translate this to polynomials
(x + 1)(x + 1)
Compute the result
x2 + 2x + 1 ≡ x2 + 1
Convert back to a bit array
0101
And now it makes sense. We were doing multiplication all along, it was just we were doing multiplication in an Galois Field 28 with polynomials represented as bit arrays. Obvious with hindsight.
Code
With the theory nailed down, we are now ready to write some code to perform addition and multiplication in these fields.
Addition it turns out it is really easy. Remember in addition we add the coefficients of each term of the same order. For our bit arrays this means adding the nth bit in each array together. Also because the coefficients are from GF(2) they can only have the values 0 or 1 and wrap around as appropriate. The following truth table shows what happens to each bit when adding them together:
a
b
Result
0
0
0
0
1
1
1
0
1
1
1
0
This is the same truth table as an Exclusive Or (XOR), and therefore we can perform addition by simply performing a bit wise XOR. In C this is the ^ operator. There is no need to even write a function, but if you really wanted to it would like something like this:
unsigned char poly_add(unsigned char a, unsigned char b) {
return a ^ b;
}
Multiplication is slightly more complicated. We have to really think about what multiplication is and break it down into smaller steps. So let's go back to school once again and do some long multiplication. If we had to multiply two large numbers together using pen and paper, we wouldn’t do it in one step, instead we would do it digit at a time.
4936
× 211
4936
49360
+ 987200
1041496
Note how for each digit of the second number we create a new line, making sure to shift the result one place to the left and add in an extra zero, finally adding the subtotals together. This shifting the subtotals to the left effectively multiplies it by 10, because we are working in base 10. We can do something similar with our bit arrays of polynomials, the effect being the result is multiplied by x.
Bit array
Polynomial
Starting value
011
x + 1
Bit shift to the left
110
x2 + x
We can use this bit shifting and addition to perform multiplication. For example to multiply the polynomial x2 + 1 by x2 + x + 1 we would do the following:
This would be correct for GF(28) but incorrect for GF(23) as this is not an element of that field. We need to reduce this value using our modulus x3 + x + 1, I’ll return to that in a moment. First let’s explore another example:
In this example the second subtotal is 0 because the second digit in the second bit array is also 0. Perhaps obvious, but worth noting that this subtotal can be skipped. Keep in mind though that even though there was nothing to add to the total, the bit shifting still happened so when we get to the third subtotal it has been shifted twice.
With all this in mind the code to perform this multiplication is as follows:
unsigned char ploy_mul(unsigned char a, unsigned char b) {
unsigned char result = 0;
for (int i=0; i<8; i++) {
if (b & 0x01) {
result ^= a;
}
a <<= 1;
b >>= 1;
}
return result;
}
The variable result is set to 0 and incrementally updated for each digit in b. The check in the if if (b & 0x01) is doing a bit wise comparison to see if the rightmost bit is set to 1 and only adding a to the result if required. The a <<=1; bit shifts the first number (a) to the left, effectively multiplying it by x for the next iteration. The b >>= 1; bit shifts the second number to the right so the next digit we need to check in the if condition is always the rightmost bit.
This code however has a problem, it doesn’t account for when the result gets too big. We know the solution is to divide the result by the irreducible polynomial and take the remainder, but how to code that and not overflow? Consider the following example in GF(23) as both a polynomial and the equivalent bit array manipulations.
Polynomial
Bit array
101 << 1 = 1010
1010 ^ 1011 = 1
The insight here is that because the bit shifting is effectively always multiplying by x, we know when an overflow is going to occur whenever the leftmost bit is 1 before we shift. We also know that because we are only ever multiplying by x, the result of the division when required will always be 1 and thus the value to subtract will always be the irreducible polynomial and will always only require one iteration to work out the reminder. We can therefore shortcut the entire division part and just perform a subtraction, which as we know is equivalent to addition for GF(2n) and for a bit array is a simple bitwise XOR. This makes the code for dealing with overflow remarkably concise.
unsigned char gf2_3_mul(unsigned char a, unsigned char b) {
unsigned char result = 0;
for (int i=0; i<3; i++) {
if (b & 0x01) {
result ^= a;
}
if (a & 0x04) {
a = (a << 1) ^ 0x0b; // shortcut for getting the remainder
} else {
a <<= 1;
}
b >>= 1;
}
return result;
}
This code works nicely for GF(23) but would not work for other fields. This is because the loop only checks 3 bits of the bit array and the modulus is encoded in that 0x0b, this is hexadecimal for the binary 1011 or the polynomial x3 + x + 1.
For AES, which uses GF(28), the irreducible polynomial used is x8 + x4 + x3 + x + 1. A new wrinkle in our code is that if we are using 8 bit integers to store our bit arrays, we can’t have an intermediate step with a polynomial higher than the 7th degree. For example we couldn’t store that irreducible polynomial as it would require 9 bits. Similarly, take the byte 1100 0001 and shift it left you will end up with 1000 0010, the leftmost 1 got truncated.
As it happens this is not an issue, if we look back at our examples, the extra term (extra bit) that is generated when multiplying by x is always cancelled out when computing the remainder as part of the modular arithmetic. In our GF(23) examples, when the left shift generates a 3rd degree term (x3) the irreducible polynomial is subtracted, which also has a 3rd degree term, removes it immediately.
Our code for GF(23) is using 8 bit integers, so it has the space to briefly create and remove the 3rd degree term. We could however ignore this term, make note when it’s going to be created to trigger the modulo arithmetic but not bother to add the then remove the term. This is exactly the strategy we need to employ for GF(28) where we do not have the space to store the 8th degree term (x8) even temporarily.
The code for AES multiplication therefore looks like this:
unsigned char aes_mul(unsigned char a, unsigned char b) {
unsigned char result = 0;
for (int i=0; i<8; i++) {
if (b & 0x01) {
result ^= a;
}
a = (a << 1) ^ (a & 0x80 ? 0x1b : 0);
b >>= 1;
}
return result;
}
When a is bit shifted, a check is made to see if the leftmost bit was 1 and would therefore be truncated and require some modulo arithmetic. If so the polynomial x4 + x3 + x + 1 (encoded in hexadecimal as 0x1b) is added/subtracted from the result. It doesn’t need the x8 term because that will have already been truncated/removed by the bit shifting.
13 lines of code
Which brings me to the end of this post. All this effort to work out how to perform addition and multiplication. Why? Well AES encryption requires a structure that supports 256 elements and two operations that can go forwards and (crucially) backwards. For that we need a field and I now know what a field is and how this one works. So with any luck I can now implement the actual algorithm.
From one particular point of view, all I’ve written so far is 13 lines of code. Not massive progress. I could have just copied these lines from any number of text books or websites and moved on. But I didn’t. I wanted to understand them. And I really do. It’s taken six months and eight thousand words to convince myself, but I can now say with well earnt confidence, I now understand the maths behind AES encryption. Well some of it.
With the web server component of Tinn built and working fairly well, it’s time to move on to the next deliverable. Looking back at my original planning, I listed the next three deliverables as the database, an interpreter and cryptography (encryption). I really want to build the interpreter next but I’ve instead decided to concentrate on cryptography first.
Cryptography is required for HTTPS, and really that is what has driven cryptography to the top of the list. While the web server works fine with normal HTTP, and I don’t yet need the security offered by HTTPS, browsers and applications are becoming increasingly intolerant of plain HTTP. For example WhatsApp on Android automatically converts all HTTP links to HTTPS even if you explicitly set them to HTTP. This is a problem for me as when I send someone a link to a blog post via WhatsApp, the page fails to load on their phone. It’s a pain. And therefore cryptography and HTTPS support becomes priority number one.
I know a little bit about cryptography, but mostly at a very high theoretical level. I know for example cryptography falls into two main camps, symmetric and asymmetric. With symmetric you use the same key to encrypt and decrypt the data, with asymmetric you have two keys and use one to encrypt and the other to decrypt. I know that we need both because symmetric is generally fast to execute but communicating the key securely is an issue, asymmetric is by comparison much slower to execute but key exchange is not an issue. I know that HTTPS uses a combination of both and a whole load of carefully thought out protocols.
I know that at a technical level symmetric encryption is mostly bit flipping and shifting and the security comes from the complexity of the algorithm which is the challenging part. The algorithm for asymmetric encryption is comparatively simple but operates on massive numbers, much larger than any CPU register so the challenge comes from having to build routines to perform maths on numbers bigger than the processor can understand. I know that key generation is tricky and making computers generate truly random numbers is impossible and at some point prime numbers are going to crop up.
I know enough to be nervous.
The good news is I have a book on the subject. I’ve been using it as a paper weight for a few months. I should probably read it instead.
I’ve been a little distracted from Tinn for a few days. Instead I’ve been building a LEGO Space Launch System.
As cool as the promotional pictures look, a concern from a LEGO building friend of mine is the build would be a little repetitive. Just look at that tower. Clearly it didn’t concern me as much because I purchased the set. My friend asked me for a review, so here goes.
Is the build repetitive? Yes. But, LEGO has done a really good job breaking up the monotony. The build predictably starts with the base, but you don’t add all the detail to it straight away. You then build a few segments of the tower before taking a break and adding some details elsewhere, then add a few more segments, then some details. As a result there is no step where you are building 12 copies of the same thing. Besides which, every section of the tower has a slight difference from every other section, so while there is an obvious pattern, there is also variation.
The rocket is built last. Again LEGO do their best to keep it interesting by mixing up the build techniques in use and jumping between the core stage and boosters. The main cylindrical parts used by the booster actually come in three varieties which I didn’t spot at first, some plain, some with printed details. This intrigues me because the set also comes with stickers.
That is my biggest criticism of the set, I’ve never met any LEGO builder who likes stickers. Sets like the Saturn V stand out in my memory because it had no stickers. This set contains a number of printed parts including the capsule which I assume is exclusive to this set, so I don’t understand why LEGO didn’t go all the way and print everything.
It’s a great looking model. It has a surprising level of detail for a LEGO model of such a huge real world structure. When looking at photos of the real SLS platform, I’m now picking out all kinds of details I’d previously missed because I just spent a week building a model version. It’s part of the reason I like these kinds of models, it gives me a better understanding and appreciation for the real thing.
I would recommend the set to any NASA/LEGO fans, especially if you already have the Saturn V, Lunar Module, ISS and Space Shuttle. If you are curious, this is how it compares side by side to the Saturn V. No surprises they are not to scale.
Oh wow, it’s the 31st of May already and I wanted to publish to the blog before the month is out. Luckily I did the coding two weeks ago and already drafted the post, I should get a move on.
I wanted to round out the functionality of Tinn to make it a compliant web server. This essentially means supporting a few more headers, correctly closing the connection when appropriate and adding support for the HEAD method.
Host header
HTTP requests must include the host header. This is so web servers hosting multiple websites on a single IP & socket know what site to return. This is a requirement for HTTP/1.1 and the server should reject any request without the header with a response code of 400, aka Bad Request. Technically it's an optional header for HTTP/1.0 but most clients include it anyway and some servers reject requests without it.
The server doesn't actually need to do anything with the header, that is outside the spec, but it must validate it. So I added the check. Currently I don't need to use it for anything, but one day I will.
Connection header
The connection header in HTTP requests defines if the connection should be closed once the response is sent or kept open. The default behaviour if the header is not supplied is dependent on the HTTP version. For 1.0 the connection should close, for 1.1 it should remain open.
I added code to read the header or set its default value if not supplied.
if (request->connection.length==0) {
if (token_is(request->version, "HTTP/1.0")) {
request->connection = default_header("close");
} else {
request->connection = default_header("keep-alive");
}
}
I then changed the response code to honour the setting once the response had been sent.
Testing this was a pain because all the common clients I use use HTTP/1.1 and either send a connection header set to keep-alive or no connection header at all. I was surprised to learn that both curl and wget don't set the connection header to close and instead close the connection themselves after receiving the response. I therefore had to break out the telnet client and craft some tests by hand.
HEAD method
A compliant server must support both GET and HEAD methods. The HEAD method generates a response that includes the same headers as a GET request but without the request body. I guess the idea is (or was) that clients could perform a HEAD request to get details about the required resource (like if it is a valid resource, when it was last modified, what size it is) before committing to a potentially costly download. The reality is I don't think any common clients take advantage of this option and as a result some professional servers don't implement support for the HEAD method despite being part of the standard.
I'm being a good developer and added support anyway. This required adding a new content source to my response module so content generators could record the content type and length without storing the actual content. I updated the static files module to record the file size (aka content length) for HEAD requests and skip the actual reading of the file. For the blog module, I still generate the response content as this is currently the easiest way to compute the content length.
Testing this was fairly easy as a -I option to curl will make a HEAD request.
> curl -I localhost:8080
HTTP/1.1 200 OK
Date: Fri, 31 May 2024 22:19:31 GMT
Server: Tinn
Content-Type: text/html; charset=utf-8
Content-Length: 242439
Cache-Control: no-cache
Last-Modified: Fri, 31 May 2024 22:17:44 GMT
Summary
With that, I am fairly confident the server is compliant with the standards, except for one thing. I did a search for all the MUST requirements in the spec, it shows up 212 times and I think I have all of the applicable ones covered except for parsing obsolete date formats in header fields. They are obsolete formats so I should be safe, still I’ll add that one to the backlog for another day.
I knew I did something wrong the morning after I updated the server because it crashed. The terminal showed a segment fault right after reporting a bad request and right before trying to output the request target. So my gut was I messed up the debug/logging code and was trying to output a null pointer or something. I had my day job to attend and plans for the evening so it would have to wait. I was tempted to roll back the deployed version but let's be real, not that many people are reading my site and no one is relying on it. Besides I have an SSH client on my phone, I could check from time to time and restart the server if I needed to. Which I did, about three more times.
Evening plans complete, it was time to go bug hunting, let me walk you through my process.
It starts with me dry running the program. That is, I imagine the program running while I read through the code one line at a time. Sometimes I use a bit of paper to keep track of variable values, but mostly I do the whole thing in my head. I was lucky enough to study computer science for A-levels and this is a skill I picked up then. We spent a lot of time dry running programs on paper in classrooms. The idea is that this slow deliberate approach lets me spot any flaws in logic so I can correct them. It solves a lot of problems.
Based on the terminal output I started by looking at the new code for parsing and storing URIs. My confusion was that I’d thought I had made this code safe with regards to bad requests. In the case of an invalid request target it should still create a safe URI structure with the valid flag set to false, a path length of zero and the path set to an empty string. After carefully reviewing the code, I couldn’t see why it wouldn’t do exactly that. It certainly shouldn’t be causing a segment fault.
I also looked at the code that called it, the new request module. Likewise that code seemed correct. I couldn’t see what was wrong.
The next step of my debug process is to try to reproduce the error. This was tricky, requests made from my browser all seemed to work, I couldn’t make the server crash. The server was also running for hours responding to multiple requests from all kinds of sources without crashing. This is why I’d not spotted the problem in my original testing. I fired up the telnet client and started experimenting with bad requests. The first test was to send an empty request and straight away the server crashed in the same way. This is a huge step forward. Once I can reproduce the error at will, I can start to experiment to find out exactly what is going on.
It didn’t take long. With HTTP requests, the header is not considered complete until the server receives a blank line. I’d written code to look for this blank line by searching for the input buffer for consecutive newlines (\r\n\r\n). Upon finding the blank line, everything before that line is the header which would then get parsed, including the request target URI. If after receiving data I did not find the new line, the request is incomplete and I would leave it alone and return to the main network loop to wait for more data.
With the telnet client data is sent to the server every time you hit enter and go to a new line. Hitting enter straight away will send a blank line, technically it will send a new line sequence (\r\n). My code looking for the end of the header will be triggered but because the entire input buffer is currently a single new line, it won’t find consecutive new lines and will consider the request incomplete, returning to the network loop to wait for more data. However before I could send a second new line the server would crash. This is because the socket listener code for clients was not checking if the request was complete before trying to read it. I was checking for errors but the code to check if the request was completed got missed in the refactor. As a result the code tried to process an incomplete request and crashed when reading the request target because this structure had yet to be populated.
The fix was simple enough. I just added a check to see if the request is complete and if not, return to the main network loop and wait for more data, like it thought it was already doing.
static bool read_request(struct pollfd* pfd, ClientState* state) {
Request* request = state->request;
Response* response = state->response;
int recvied = request_recv(request, pfd->fd);
if (recvied <= 0) {
if (recvied < 0) {
ERROR("recv error from %s (%d)", state->address, pfd->fd);
} else {
LOG("connection from %s (%d) closed", state->address, pfd->fd);
}
return false;
} else if (!request->complete) { // new check
return true; // true because we want to keep the socket open
} else {
// process request
// …
// send
return send_response(pfd, state);
}
}
I didn’t spot this error when first investigating because I was too deep into the stack and I was focusing on the new URI and request code. I didn’t consider the (relatively) older socket listener even though I had made quite a few changes to this code. So many times finding the cause of a bug results in a “d’oh” moment. How did I miss that and why didn’t I look there first?
Also, as is often the case, once I understood what is wrong, the fix is comparatively easy. Bug hunting is mostly about the hunt. I often have to reassure my team as they try to justify why it took them several hours to find and understand a problem before changing a few characters of code. “I get it” I tell them, “I’m a programmer too”.
I want to update the server so it better detects changes on the file system. At the moment it doesn't really do that. This came from my paranoia about the server accidentally serving files I didn't want it to. My strategy was to scan the content folder, build a list of valid paths and validate incoming requests against that list.
As I stated at the time this gave me confidence in what was being served, but I would need to restart the server every time I added content. Most of the time this is fine. But when I'm writing and proofreading new posts, it's a bit of an annoyance. More so with blog posts because they are partially generated and only generated when the routes list is built as the server starts.
It’s interesting how you can normalise annoying things. I got used to saving the source file, killing the server, re-starting it and then refreshing the page to continue my review. I recently was doing some development at work and not having to continually restart the server was really refreshing. It shouldn’t be, it should be the norm and highlighted it was time to fix this in Tinn.
I’ve had some time to think about this and my new strategy is to ditch the pre-built list of routes. Instead I shall first validate the incoming URL to make sure it’s not doing anything sneaky and then pass that url to the various…err…content generators. I wanted to say “app”, but we’re not there yet. For now I have two content generators, the blog and static files. The routing code will ask each generator in turn if it wants to deal with the url, if it doesn’t it will ask the next and so on. If they all decline, I’ll return a “404 - Content not found” error. In the future if I add any other content generating code, it can get added to the list of content generators to query.
Validating the request target
I'm thinking that I should break the requested path up by directory. Then look to see if any of those directories are . (aka the current directory) in which case I could ignore them, or .. (aka the parent directory) in which case I should jump back a level. I should keep track of how many levels deep I am and if a .. tries to access the content directory’s parent, throw an error. The result would be a canonical path without any jumping back and forth and I think it would be safe from escaping the content directory.
I thought I should double check the spec and make sure I understood the format of the incoming URI. This actually means looking at four RFCs, HTTP/1.1 (9112), HTTP (9110), Uniform Resource Identifier (3986) and Augmented BNF for Syntax Specifications (5234). It’s exciting stuff. Anyway the most relevant information starts in section 3.2 of HTTP/1.1 which describes the request-target. There are actually four formats for request targets however only one applies to GET requests, so I only have to worry about the origin-form format.
This is basically what I expected, a path which consists of a sequence of segments separated by a forward slash (/). I’ve just learnt that the bits in a path between the slashes are called segments. The . and .. segments are called dot segments and it seems there is a well established algorithm for resolving these relative parts into an absolute path. Reassuringly it matches my thoughts above.
Otherwise the segments can have quite a large range of characters, really most things except a forward slash or a question mark (?). No slash because this delimits the segments and no question mark because this denotes the end of the path and the start of the query. In other contexts, web browsers for example, we would also be looking for the hash (#) to end the path and start the fragment, but on the server side this is invalid, in fact the hash is simply not allowed anywhere in a request-target.
I was surprised by the range of other characters segments could have. There were several I thought would be invalid, for example colon (:), which is fine apparently. This is because I was thinking about what would be acceptable characters for file names and I was thinking about Windows. I made two mistakes here. First, paths in HTTP don’t have to relate to file systems, they often do, but they can be interpreted by the server in any way the implementer (in this case me) wishes, and the spec is open enough to allow that. Second, it turns out that colon is a valid character for file names in Linux. It seems Linux can support any character other than null and forward slash, some are problematic and probably best avoided but they are supported.
If you collect together all the relevant Augmented Backus-Naur Form (a language used to describe formal languages) for the definition of the origin-form type of request-target you get the following:
If you can read it, this tells you a lot of things you need to know about request targets. One of my questions it answered is you can’t have a blank target, you have to have at least one forward slash. As it happens, all origin-form request targets start with a forward slash. It also clarifies exactly what characters are allowed in a request-target. It’s very helpful when doing what I’m about to do next, which is write code to validate an incoming request.
sometime later
I created a new data structure URI to store the various parts of the target request.
I coupled this with a new uri_new function to populate the structure and as is my habit a uri_free to clean up. The uri_new function takes a Token, this is the target I already extracted from the request’s start line. I felt the urge to build a parser that did both jobs in one but resisted for now. After allocating space for the actual structure, it allocates space for a copy of the token, the address of which is stored in the data property. This copy will be chopped up into the various parts later but for now I just append a null terminator.
The function then populates the other properties with some default values. The path gets set to NULL for now. query is set to point at the last character in the data string, which is a null terminator, making query an empty string. Space is then allocated for segments which is an array of character pointers and will be used to point to each segment in the path.
The last of the setup code sets the valid property to true. If I hit any problems with the URI later I’ll change this. Which brings me to my first check, ensuring the URI starts with a forward slash.
uri->valid = true;
// validate URI starts with a forward slash
if (token.length==0 || uri->data[0]!='/') {
uri->valid = false;
return uri;
}
Now for the real work. Checking each character in the URI in turn. If it’s a forward slash I’ve found a segment boundary. If it's a question mark I’ve found the start of the query. Otherwise I need to check if the character is in the list of valid characters.
When finding a question mark, I change the question mark character (in the copy of the string pointed to by data) into a null terminator. This is so any string functions reading the path before this point will now stop here. I then update the query property to point to the next character so I can access the query string as needed. Reading the spec closely shows that forward slashes and question marks are valid characters in queries. Any special meaning they may have is up to whatever is parsing the query to determine. Therefore I need to keep track of whether I'm processing the path or the query and act appropriately when I find a forward slash or question mark. To do this I set the simple in_path flag set to true initially and change it to false when I find the first question mark.
// scan the URI looking for segments (directories), the start of the query
// and invalid characters
bool in_path = true;
for (int i=0; i<token.length; i++) {
switch (uri->data[i]) {
case '/':
if (in_path) {
// create a segment...
}
break;
case '?':
if (in_path) {
uri->data[i] = '\0';
uri->query = uri->data + i + 1;
uri->query_len = token.length - i + 1;
in_path = false;
}
break;
default:
if (strchr(valid_chars, uri->data[i])==NULL) {
uri->valid = false;
return uri;
}
}
}
To validate other characters I use the library function strchr to get the characters position in a string that contains all the valid characters. If this returns NULL the character is not in the string and therefore not valid.
The code to process segments is a bit more complex. First I need to make sure I have enough space in the array and expand it if required. Then like with the query, I replace the forward slash with a null terminator and point the next segment in the array at the next character.
case '/':
if (in_path) {
if (uri->segments_count == max_segments) {
max_segments *= 2;
uri->segments = allocate(uri->segments, max_segments * sizeof(*uri->segments));
}
uri->data[i] = '\0';
// deal with dot segments?
uri->segments[uri->segments_count++] = uri->data + i + 1;
}
break;
The complexity comes from dealing with dot segments. This is a fence post problem. When I find a forward slash, the fence post in this analogy, I need to consider the segment before and after the slash, the fence panels either side of the post. I need to review the previous segment, which I can now do because it’s complete, and check if it was a dot segment and then remove it. This is where the fence post analogy falls apart. Pretend I didn’t mention fences. Basically I have to look forwards and backwards. And, this is a common pitfall in this kind of problem, remember to process the very last segment.
I wrote a helper function to review the previous segment and manipulate the segment count if it’s a dot segment. If it’s a single dot, reduce the count by one because I don’t need the previous segment, if it’s two dots reduce the count by two because I don’t need the previous two. Otherwise leave the count alone. I added some validation to ensure I don’t go negative, which should also ensure I don’t leave the content directory.
static bool remove_dot_segment(URI* uri) {
if (uri->segments_count>0) {
if (strcmp(uri->segments[uri->segments_count-1], ".")==0) {
uri->segments_count--;
} else if (strcmp(uri->segments[uri->segments_count-1], "..")==0) {
if (uri->segments_count>1) {
uri->segments_count -= 2;
} else {
uri->valid = false;
return false;
}
}
}
return true;
}
The final task performed by the uri_new function is to re-assemble a path without any of the relative dot segments and save this to a new string pointed to by the path property. This has to be its own memory because the data string has been well sliced up with null terminators by this point.
Testing this code required more than just pointing my browser at the server with various paths. This is because the browser did some relative path resolution of its own. Type in http://www.moohar.com/a/b/../c and the browser will remove the /../ before it sends the request. Chrome won’t even let you copy it out of the address bar before it updates it. You might ask if the browsers already handle relative paths, why did I just code a solution for them? Well I haven't tested every browser and there are other ways of making HTTP requests and the evil hackers don’t play by the rules. So I used telnet to test.
I modified the server while I was testing to return a simple page with just the resolved path so I could check it was working. Therefore this test was a success. I also tested trying to escape the content directory, which thankfully was detected and the server returned an error.
GET /../secret.txt HTTP/1.1
HTTP/1.1 400 Bad Request
Date: Sun, 21 Apr 2024 20:18:33 GMT
Server: Tinn
Content-Type: text/html; charset=utf-8
Content-Length: 99
<html><body><h1>400 - Bad Request</h1><p>Oops, that request target seems invalid.</p></body></html>
I did discover an edge case if the very last segment was a dot segment. The path /a/b/c/. will resolve to /a/b/c which is incorrect, it should resolve to /a/b/c/. The path /. resolves to nothing, it should be /, which is how I spotted the error. Similarly /a/b/c/.. resolves to /a/b when it should resolve to /a/b/.
I corrected the problem by updating the remove_dot_segment, it now takes an extra parameter to flag when it’s processing the last segment. I updated its behaviour so instead of removing the last segment if it’s a dot, it changes it to an empty segment.
Before I move on I also had to decide what to do with empty segments. For example /a//b is a valid path with three segments: a, an empty segment and b. There is no guidance in the spec in how to treat these. Chrome leaves them alone, backing up my interpretation that they are valid segments. File systems ignore them, /a//b is equivalent to /a/b and /a////////b. The rest of the internet (yes, I checked all of it) is undecided what to do. They are valid, but they mess up search engines probably and caching maybe and should just go away. I made sure they didn’t break my code but otherwise left them as empty segments...for now.
I need to update the blog code to stick around and deal with requests on demand. Currently, as previously explained, it generates all the blog pages when the server first starts and then it’s gone leaving the current routes list code to deal with serving the content. If it’s going to detect changes it needs to stay active and be responsible for serving its own content.
The code already generates a list of posts, so that is not a problem, I just need to not dispose of it and keep a pointer to it…somewhere…let’s ignore that detail for a moment. I can check the request target against this list to work out if the target is a valid post. But before I do that, when processing a request I can first check the modified date of the posts file vs when I last parsed it to work out if a new post has been added and I need to re-generate the list. Then I can check the list. If it is a valid post I can check the associated source file and double check its last modified date to see if I need to re-generate the page content. There are a few checks and lists and buffers to manage, but it all seems to make sense and I can just about visualise the code I need to update/write.
I will also need to write a static files module. This will check a request target against the file system to see if the path matches a file and if so, serve it. There are opportunities for caching here, and if I do I will need to check the cached date vs the file modification date to work out if I need to refresh the cached version. I can borrow code from the current routes list and elsewhere, I don’t see this as particularly problematic.
Next question, how does the code that has processed the incoming request (the code in client.c) talk to the content generators (the blog and static file modules)? Via a function call of course. I think I know what the signature of that function will be, the client code passes the content generator the parsed request target and the content generator returns a buffer with its response or NULL if it has none. Except that won’t work. What if the content generator wants to return a redirect or set response headers? The response needs to be more flexible than just a buffer with the response text. Also the content generator needs more than just the request target, it needs to read other headers like If-Modified-Since to work out if it can return a simple 304 - Not modified instead of the full content.
At the moment the request and response data is being held in the ClientState structure with the functionality being hidden inside client.c. I feel I need to break this into request and response structures and open up the functionality so I can build responses from the content generators.
Which brings me back to how to keep a pointer to the blog list and how does the client code access it? I could create a global variable. It would work, but this won’t scale well as I add more content generators. Besides, globals will come back to haunt you. I reviewed how the current routes list works. It is created in the main function all the way back at the start. Then as part of the main network loop, the socket listener gets passed the routes list. It’s part of socket_listener typedef in net.h:
typedef void (*socket_listener)(Sockets* sockets, int index, Routes* routes);
This will have to change. Instead of routes, the main function will build a list of content generators and pass that to the socket listeners instead. I’m just debating in my head if that is the best way to do it, it seems something very specific to a particular type of socket listener (HTTP client requests) but the rest of the code in net.c is generic and could be used for any socket listening. The socket list already has a generic state pointer for storing data specific to that socket. I should use that mechanism instead.
Which completes my plan. To summarise, to update the server so it can detect changes I plan to:
update the blog module;
create a static file module;
split the client response code into request and response code;
delete the current routes list;
change the socket list; and
tweak the main network loop.
A small warning alarm is going off in my head. The scale of change is an indicator I’m over engineering this. I will sleep on it.
some sleeping later
I've slept. I showered, went to work (it was a manager hat day), went to the gym and jumped around, showered again, ate, then had a quick nap. I still think this is the correct path. So excuse me, I have code to write.
some typing later
I did this in phases.
1. Scaffolding
I started with the scaffolding for defining a list of content generators, populating that list, passing it around and calling the content generators to generate content. This started by defining what that function would look like. After some refinement I landed on the following function signature:
As I described before, this will be the interface between the network code and the content generating code. All the details of the request will be in the Request structure. The function can use the Response structure to return the response. I initially created some place holders for these structures each containing a buffer.
The function also takes a void pointer I’ve labelled state. The intention is this will point to a structure containing all the data that the content generator needs. For example the blog structure will contain the list of parsed blog posts.
To close off the function, it returns a boolean to indicate if it generated a response or not.
Next I needed a list of content generators. This code follows a very familiar pattern to list code I’ve used elsewhere. A structure to store all the variables required, and some functions to create a new list and add entries to it.
I updated the code in the main function of tinn.c to remove the routes code and instead create a list of content generators.
// create content generators
TRACE("creating list of content generators");
ContentGenerators* content = content_generators_new(2);
content_generators_add(content, blog_content, blog_new());
content_generators_add(content, static_content, NULL);
I updated the socket_listener typedef so it no longer took a routes list as its third parameter. This required me to update the server_listener function (which it used to ignore the routes list anyway) and the client_listener function which would now need the list of content generators instead. As planned I used the state pointer in the socket list to store the list of content generators.
The main function now calls the server_new function to create the server socket and passes it the content generators list. This function saves the content generators list in a ServerState structure and stores this in the socket list.
void server_new(Sockets* sockets, int socket, ContentGenerators* content) {
int index = sockets_add(sockets, socket, server_listener);
ServerState* state = server_state_new();
state->content = content;
sockets->states[index] = state;
}
When the server accepts a connection and creates a new client socket/listener, it passes the pointer for the content generators list to the client.
static void server_listener(Sockets* sockets, int index) {
// … other code …
client_state = client_state_new();
client_state->content = server_state->content;
// … more code …
}
The client listener can now loop though this list to call each content generator in turn.
This is a lot of change to a lot of parts of the program. It’s mostly list management and passing that list to the parts of the program that need it. With the placeholder code it was possible to get this code to compile so I could test new code worked as expected.
2. Request
Next I moved the responsibility for reading requests to the requests module and expanded the Request structure to include all the fields content generators might need. Primarily this means the request target, method and headers. Currently I’m only extracting the one header (If-Modified-Since) but as more are required they will go here.
Most of the associated code to read the request was already written and I simply moved it from client.c to request.c.
3. Response
The response module was a little more complicated. This is because I wanted to add some flexibility and resilience to how the response is composed. For example I didn't want to have to set the status code before setting any other headers. As the status code is on the start line of the response, if I only use a buffer to compose the response I have to set and write it first. Equally I wanted to be able to set the same header twice but only output it once. This would allow me to set the header to a default value and then later change it should I need to.
To achieve this I added a field to the Response structure to store the status code until I needed it. I also added two arrays for header names and values (and some fields to track the number of headers set).
typedef struct {
int status_code;
size_t headers_size;
size_t headers_count;
char** header_names;
char** header_values;
// err, is this still right? no.
Buffer* buf;
} Response;
I then created a response_header function to set a header. This checks the current arrays to see if the header is already set, if it is it will overwrite the value, if not it will create a new entry for the new header. It also deals with all the memory management for the strings, using a utility function copy_string I wrote to copy the incoming header and value strings. This seems wasteful of memory, I need to think about it some more, but I was aiming for safety first.
I also wanted some flexibility with regards to the response content. I needed to support responses with no content, for example a 304 response to use the cached version doesn’t need any content. When there is content, I imagined a scenario where I want the response module to manage the buffer for the response content and one where some other part of the program would manage the buffer. So three sources for content in total: none; internally managed; externally managed.
I updated the Response structure again, this time with three new fields. content_source is used (with some handy macro constants) to indicate the three sources of content. A content field which is a pointer to a buffer for the actual content. Finally type a string with the HTTP content type for the Content-Type header.
typedef struct {
int status_code;
size_t headers_size;
size_t headers_count;
char** header_names;
char** header_values;
unsigned short content_source;
const char* type;
Buffer* content;
// seriously now, this placeholder is no longer needed?
Buffer* buf;
} Response;
I created three functions for each of the three sources of content. response_no_content is the simplest, setting the source to NONE. It does however first check if the content source was previously INTERNAL and if so, frees up that buffer as it is no longer needed. response_content sets the content source to INTERNAL and creates the buffer (if it’s not already created). response_link_content sets the content source to EXTERNAL and saves a pointer to it. The latter two functions both take a type parameter to set the HTTP content type.
With all the data it needs to compose the response, I moved the responsibility for actually sending the response to the new response module. First it would need to convert all the stored headers to a single string, then send the headers and then send the content if there was any. I needed a state variable to track where it was in the process, which for some reason I called stage, and a buffer for the stringified headers. The Response structure evolves into its final form:
typedef struct {
int status_code;
size_t headers_size;
size_t headers_count;
char** header_names;
char** header_values;
unsigned short content_source;
const char* type;
Buffer* content;
Buffer* headers;
unsigned short stage;
} Response;
The stage starts in PREP while content generators do their thing. On a call to the response_send function if the stage is still PREP the headers get built and the stage is incremented to HEADERS.
static void build_headers(Response* response) {
TRACE("build response headers");
// status line
buf_append_format(response->headers, "HTTP/1.1 %d %s\r\n", response->status_code, status_text(response->status_code));
// date header
buf_append_str(response->headers, ": ");
to_imf_date(buf_reserve(response->headers, IMF_DATE_LEN), IMF_DATE_LEN, time(NULL));
buf_advance_write(response->headers, -1);
buf_append_str(response->headers, "\r\n");
// server header
buf_append_str(response->headers, "Server: Tinn\r\n");
// content headers
if (response->content_source != RC_NONE) {
buf_append_format(response->headers, "Content-Type: %s\r\n", response->type);
buf_append_format(response->headers, "Content-Length: %ld\r\n", response->content->length);
}
// other headers
for (size_t i=0; i<response->headers_count; i++) {
buf_append_format(response->headers, "%s: %s\r\n", response->header_names[i], response->header_values[i]);
}
// close with empty line
buf_append_str(response->headers, "\r\n");
response->stage++;
}
The send code then works though the headers buffer sending the data to the client in a non-blocking way as I described in the Biggish files post. The difference here is once it’s done with the headers buffer it will increment the state to CONTENT and on subsequent calls to the function work though the content buffer (assuming there is content).
ssize_t response_send(Response* response, int socket) {
if (response->stage == RESPONSE_PREP) {
build_headers(response);
}
if (response->stage == RC_NONE) { // just in case?
WARN("trying to send a request that is finished");
return 0;
}
Buffer* buf = (response->stage == RESPONSE_HEADERS) ? response->headers : response->content;
size_t len = buf_read_max(buf);
ssize_t sent = send(socket, buf_read_ptr(buf), len, MSG_DONTWAIT);
if (sent >= 0) {
TRACE("sent %d: %ld/%ld", response->stage, sent, len);
if ((size_t)sent < len) {
buf_advance_read(buf, sent);
} else {
response->stage++;
if (response->stage == RESPONSE_CONTENT && response->content_source == RC_NONE) {
response->stage++;
}
}
}
return sent;
}
The calling client code will keep calling this send function (and deal with all the socket stuff) until the response reaches the DONE stage.
4. Static content
Next I built the static files content generator. This basically involved expanding the placeholder function static_content into a working function. Most of the logic for this came from the old routes list code, specifically the routes_add_static function but updated to work with the Request and Response structures.
As the function is going to manipulate the request target a little bit to translate it for local use, I start by creating a copy of the path and extracting the last segment.
// build a local path
char local_path[request->target->path_len + 1 + 11 + 1]; // 1 for leading dot, 11 for possible /index.html, 1 for null terminator
local_path[0] = '.';
strcpy(local_path + 1, request->target->path);
char* last_segment = request->target->segments[request->target->segments_count-1];
Then time for some of that manipulation. I check to see if the last segment is empty, if so the request is for a directory and so we should instead look for index.html in that directory and I update the path and last segment appropriately. At some point I will probably need to expand that to look for other index files, but for now, index.html is all that Tinn supports.
I don’t want to serve any dot files, so the next check is to see if the last segment starts with a . and if so exit with a false, aka no content generated.
I then try to read the file information. If this fails then there is no file at the request path and again I exit with a false.
// get file information
struct stat attrib;
if (stat(local_path, &attrib) != 0) {
TRACE("could not find \"%s\"", local_path);
return false;
}
If I found a file I check if it was really a file or a directory (or something else). For files I check the modification date and either return a 304 to use the cached version or the file contents otherwise. This code was moved from the prep_file function in client.c and updated to use the new response module.
if (S_ISREG(attrib.st_mode)) {
TRACE("found \"%s\"", local_path);
// check this is a GET request
// TODO: what about HEAD requests?
if (!token_is(request->method, "GET")) {
response_error(response, 405);
return true;
}
// check modified date
if (request->if_modified_since>0 && request->if_modified_since>=attrib.st_mtime) {
TRACE("not modified, use cached version");
response_status(response, 304);
return true;
}
// open file and get content length
long length;
FILE *file = fopen(local_path, "rb");
if (file == NULL) {
ERROR("unable to open file \"%s\"", local_path);
return false;
}
fseek(file, 0, SEEK_END);
length = ftell(file);
fseek(file, 0, SEEK_SET);
// respond
response_status(response, 200);
response_header(response, "Cache-Control", "no-cache");
response_date(response, "Last-Modified", attrib.st_mtime);
char* body = buf_reserve(response_content(response, strrchr(last_segment, '.')), length);
fread(body, 1, length, file);
fclose(file);
return true;
}
If it’s a directory I check to see if that directory has an index.html file and if so return a 301 redirection to a path with a correctly trailing forward slash as described in the Routing post. If there is no index, I don’t redirect, I don’t want to redirect to then return a 404, I would rather just return the 404 straight away.
if (S_ISDIR(attrib.st_mode)) {
TRACE("found a directory \"%s\"", local_path);
// check for index
strcpy(local_path + 1 + request->target->path_len, "/index.html");
if (stat(local_path, &attrib) == 0) {
if (S_ISREG(attrib.st_mode)) {
TRACE("found index, redirecting");
char new_path[request->target->path_len+2];
strcpy(new_path, request->target->path);
strcpy(new_path + request->target->path_len, "/");
response_redirect(response, new_path);
return true;
}
}
TRACE("no index");
return false;
}
If the file type is something else I log an error and move on generating no content. I guess this will come to hurt me if and when I serve content that includes symbolic links…look forward to a post with me fixing that one.
5. Blog content
Almost there.
As a reminder, the plan is to update the blog module so it persists. This means creating a structure to store all the various data it needs to keep track of. Mainly this is the list of posts, but also the various HTML fragments that are used to build the blog pages.
You’ve already had a sneak peak of the blog_new function. It gets called in the main function when defining the content generators. As you might expect it allocates memory for the structure and the posts list, creates the buffers for the HTML fragments and then calls read_posts to populate the list of posts.
The read_posts function is largely unchanged from how it was before. It reads the posts file, validates each entry and adds it to the posts list. The important change being where the post list file is stored, before it was a local structure, now it’s in the new Blog structure. Otherwise the only real change is if any particular post fails validation it now just skips just that entry and not the entire file.
The old blog_build function has been replaced by the new blog_content function. Where before all the pages were generated upfront and stored in the routes lists, now each page is built on demand using the new response module.
bool blog_content(void* state, Request* request, Response* response) {
TRACE("checking blog content");
Blog* blog = (Blog*)state;
// check home page
if (strcmp(request->target->path, "/")==0) {
TRACE("generate home page");
response_status(response, 200);
Buffer* content = response_content(response, "html");
buf_append_buf(content, blog->header1);
buf_append_buf(content, blog->header2);
for (size_t i=0; i<blog->count; i++) {
TRACE_DETAIL("post %d \"%s\"", i, blog->posts[i].title);
if (i > 0) {
buf_append_str(content, "<hr>\n");
}
compose_article(content, blog->posts[i]);
}
buf_append_buf(content, blog->footer);
return true;
}
// ... check other pages ...
6. Detecting updates
I’m now, eventually, in a position to do what I set out to do. I can update the blog module to detect updates to the file system. Let's start with some helper functions, one to get the modified date (and time) of a file and another to compare to dates (and times) and return the latest one.
static time_t get_mod_date(const char* path) {
struct stat attrib;
if (stat(path, &attrib) == 0) {
return attrib.st_mtime;
}
return 0;
}
static time_t max_time_t(time_t a, time_t b) {
return a>=b ? a : b;
}
I updated the Blog structure to include a mod_date field which will store the modified date of the posts file when I read it to generate the list of posts. Then in the blog_content function I added the check to see if the file had been updated since that date, and if so re-read the file.
// check for changes
if (get_mod_date(POSTS_PATH) > blog->mod_date) {
reread_posts(blog);
}
I did the same to the posts themselves, adding a mod_date field to the post structure and checking that date against the file’s modified date and re-reading the content if required.
I also had to add checks to the HTML fragments, checking each of those before generating any content. This finally pushed me to move the fragments into an array so I could use a loop to check and update them as required. This required a new structure for each fragment and an update to the Blog structure.
I needed to apply some thought to when I needed to perform each check and when each page would be considered stale.
I check the posts file every time, and if it’s changed I consider everything to be stale and need to re-read everything. The logic to work out which posts could be considered still fresh in this scenario can wait for another day.
I check the HTML fragments every time too, again if any of them have changed everything is stale.
If the source file for an individual file has changed it makes its own page stale, but also the home and log pages, therefore I check every post when loading those pages. It doesn’t affect the archive page as this only has content from the posts file.
With all this in place, I have achieved my objective. I can now update the posts file, the individual posts or any of the fragments and just need to refresh the page the browser to see the updates. No longer do I need to restart the server. Yay!
The other reason I did this
I now have a last modified date for each blog page. This means I can also enable client caching on these pages. Excellent.
This all seems like a lot of effort to just make the server detect file system updates. The reality is I’ve done much more than that. I’ve built a more robust and expandable system for reading the incoming request and generating a response. This has set myself up for adding app support later, which is a key goal of this project. So it was well worth the effort.
Besides, I really like not having to restart the server when doing web development stuff.
This was supposed to be a quick simple thing but it turned into an adventure down a rabbit warren.
The problem
I’ve got my development laptop, a test machine and the main server. Sometimes I lose track of what version of the Tinn executable is on each machine. To address this I added the TINN_VERSION macro to the code a while ago. When the program starts, the first thing it does is output that value to the terminal. It works except I need to remember to update that value when the version changes. This is a semantic version number and currently only the core version with the major, minor and patch numbers. It doesn’t therefore change every time I compile the code. This means there could be different executables with the same version number, which is especially true when I’m testing (which is all the time). I need something more, I need a build number or build date and I need that to be added to the program automatically every time I compile it.
Plan A
My first instinct was I could just do this with a preprocessor macro. In my head I had equated macros with code that is run at compilation time, so I could use some macros to inject the date or a build number into the code somewhere. As I’ll explain in a moment, my understanding was correct but incomplete so (spoilers) this won’t work.
There are some predefined macros I could use, __DATE__ and __TIME__ look promising. The description for __DATE__ is “the compilation date of the current source file” which at first seems to be exactly what I need. Except it’s not. There are two problems, first the format of this date is unhelpful, second the “current source file” is not what I really need.
The format of this date is mmm dd yyyy for example Apr 17 2024. It hopefully goes without saying I can read and understand that date, so strictly speaking it would work for my purposes of identifying when the file was compiled, but I’m not an American so month-day-year looks ugly to me. Being from the UK I use day-month-year when dates are written as text. But when writing a date as a number I use year-month-day, because that's how numbers work, the most significant part should be on the left. If you’ve ever tried to sort dates you know I’m right.
Unfortunately there are no options in the C preprocessor to change this. There are no options to get the date in a numeric or ISO 8601 format. There are no options to manipulate the value generated by __DATE__ into a standard format. I found some verbose examples on-line that claim to work, but when you dig a little deeper they only work with the C++ preprocessor.
All that said, the format is a moot point because even if I reformat it, the value will be incorrect. To understand why you have to understand the C compilation process a little bit. There are better writeups out there than what I’m about to present, and I’ve squished some steps together for the purposes of this post. Broadly speaking the C compilation process goes like this:
The preprocessor takes the source code and converts all the macros it contains into normal C code
The compiler and assembler turns the processed C source code into object code
The linker joins all the objects together to make an executable
By default, the C compiler does all this for you in sequence, source code goes in, executable comes out and you don’t need to worry about the intermediate steps.
You can, if you desire, break the process down and save the intermediate results. For example with the GCC compiler the -E option will only run the preprocessor and output the expanded preprocessed C code to the terminal (technically standard output). Possibly useful if you want to debug what your macros are doing.
The -c option will run the first two steps and then save the resulting object code in a .o file. Then quite separately you can link the object files together along with any libraries and whatnot into an executable. Why do it this way? As I described in my last post, it can save compilation time. Each step can be quite time consuming. If you have a massive project with lots of source files, you can run steps one and two in advance and save the resulting object file. Then if you make any modification to the .c source files, you only need to re-run steps one and two on the modified files. Then link the resulting object code to the object code from all the other files you’ve already compiled.
Since I broke the Tinn project into multiple source files and started using Make to manage the build. This is basically the process I follow. New object files are created for any source files that have been modified and saved. The object files are then combined into the executable.
What does this have to do with build numbers? Well in my example, I updated the main function in tinn.c to output the build date using the __DATE__ macro. The first time I compiled the code, step one turned the __DATE__ macro into a string literal with the current date and inserted that into the extended c source code. The second step compiled this into object code and saved the result in a tinn.o file. Then, after all the other source files had also been compiled to object code, the linker generated the executable. So far so good. When I run the program it outputs the current date as a build date, which is correct.
The problem occurs on the next day when I work on another part of the program. If for example I make an update to the client.c source file, when I compile the program, Make will recognise I’ve updated that file and will re-run steps one and two generating a new client.o file. tinn.c has not been touched, so the linker can re-use the tinn.o file generated the day before. All the object code is linked together and the new executable is ready to go. When I run the program it outputs the previous day's date as the build date, which is incorrect. This is because the date was computed the day before when the pre-processor ran on the tinn.c file and that was baked in as a literal value into the object file.
So while macros do evaluate at compile time, depending on your build process they may not be evaluated every time. So to make this work I would need to force any file that uses the build date to be completely compiled every time. Currently this would only affect one file (tinn.c) but it seems like a trap. Added to my discomfort at the format of __DATE__ value, it was time for plan B.
Plan B
Google it. This isn’t an original problem, other smarter people than me have surely solved this already. Oh, apparently not really. Well yes, people have solved it, but it’s all a bit hacky.
I found a lot of hits for people using rc files in Visual Studio to add version information to the executable, this seemed like a very Windows centric approach, something to investigate later if (when) I switch to getting this to work on Windows. It did however point me in the direction of using the linker instead of the preprocessor.
I found some posts about how in Visual Studio you can create pre-build scripts to generate a source file with the date/build number. Not helpful to me, I’m not using Visual Studio or an IDE really. I am using Sublime as my text editor, which does have a build system and scripting, so a possible option if I can’t find something else. I’m also already using Make, and this seemed like the obvious next step.
I found a tutorial by Mitch Frazier that uses Make and linker symbols. It all seemed very straight forward, the linker (step three) could inject a value (the build date or number) into the executable. Except I will soon discover that's not how linker symbols work. Anyway, using the linker over the preprocessor made sense to me as it is used every time the executable is generated so it would always generate an accurate date.
Adding a linker symbol was achieved by passing some arguments to the compiler. Specifically:
Then, to get the value of the symbol you read that variable’s address…wait what now?
Symbols are not variables. They look like variables, but really they are just memory addresses, I think. I have a very loose understanding of this, but here goes. When an executable is generated, all the instructions and functions and constants and literals etc need to be stored somewhere in the resulting file. Each one of these normally has a name and the linker will list all these names and what address you can find its definition at. For example in the last build of Tinn, the main function can be found at address 4a10. This is what a linker symbol is, it maps names to addresses.
The arguments I passed to the compiler simply created a new symbol called __BUILD_DATE which points to memory address 20240417. It didn’t create anything at that address and I’ve got no idea what is at that address. In fact reading that address is undefined behaviour, although very probably a segment fault. The trick is I don’t care what is at that memory address, I just want the address which I can then use as a value.
It’s a clever idea, a bit hacky, but should fit my needs. Problem is I couldn’t get it to work. The tutorial is from 2008 and I get the feeling things have changed a little since then. Specifically the number the program output never matched the number I passed to the compiler. I used the nm (name mangling) command to output all the symbols and their values from the executable file, this confirmed __BUILD_DATE was added and set to 20240417 aka the date, but when I ran the program it would always output a much larger value.
My assumption is there is some relative address thing going on. When the program runs the address of the __BUILD_DATE is the address in the symbol table plus the start address of the program. I sort of confirmed this by adding a second linker symbol called __START with the value of 0 then outputting the difference between the address of this and __BUILD_DATE.
I could have declared victory at this point and moved on, but because I felt like I’m abusing linker symbols and I’m not really sure what I’m doing is safe. I decided to look for other solutions.
Plan C
Use a linker script to insert a value properly into the executable? Maybe, one day. But that seems like a whole other language I would need to learn to just add a build date. Next.
Plan D
Use Make to generate a C source file with the build date in it. Some of my googling way back at the start of plan B pointed me in this direction and having got my head around makefiles some more and the C compilation process a lot more I think I could do it. The key is to do it in such a way the file is only generated if at least one other source file has changed and whenever at least one source file has changed. This way the date is always updated when it is needed but only when it is needed.
I started with some prep-work and created a version.h header file. This contains the semantic version information (which I update manually as needed) and the declaration of an external constant string called BUILD_DATE:
If I was doing this by hand, I would then create a version.c file that contained the definition of that variable:
const char* BUILD_DATE = "2024-04-17T23:06Z";
But I’m not. I want to generate that file automatically. Time to modify the makefile. The makefile has this code to build the executable.
# link .o objects into an executable
$(BUILD)/$(TARGET): $(OBJS)
@$(CC) $(COMP_ARGS) $(OBJS) -o $@
The target $(BUILD)/$(TARGET) translates to ./build/tinn. The dependencies $(OBJS) is the list of object files that is computed earlier in the file by searching for all the .c files in the src directory and translating the file names to .o files.
Through some recursion magic wherever I go to build the executable, Make will check each of those object files and each of its dependencies and if anything has changed, recompile that object file and then the executable. If none of the object files dependencies have changed, then none of the object files need to be recompiled and nor does the executable. This is therefore where I need to insert my new build date generating code.
# link .o objects into an executable
$(BUILD)/$(TARGET): $(OBJS)
# !! generate build date here !!!
@$(CC) $(COMP_ARGS) $(OBJS) -o $@
I don’t really want to store the version.c file in the src directory. If I did that, it would get picked up by the call to find in the makefile and added to the list of source and object files to monitor. I don’t really need the source file at all, I only really need its object file so I can link it in later.
The compiler can be set to accept input from standard input instead of a file. For example:
gcc -xc -c - -o test.o
In this call to the GCC compiler the -xc informs it that it’s compiling C code, this is required because with no file and no file extension, the compiler needs to be told what language it’s compiling. The -c instructs it to stop before linking and generate an object file. The lone - is where normally the input file path would be, in this case in informs the compiler to instead use standard input. Finally the -o test.o set the output path.
I can use a call to echo to generate the text for the source file with a call to date to generate the date. I can then pipe that to the call to gcc.
VERSION := $(BUILD)"/tmp/version.o"
# link .o objects into an executable
$(BUILD)/$(TARGET): $(OBJS)
@echo "const char* BUILD_DATE = \""$(shell date -u "+%Y-%m-%dT%H:%MZ")"\";" | $(CC) -xc -c - -o $(VERSION)
@$(CC) $(COMP_ARGS) $(OBJS) $(VERSION) -o $@
The only other change required is to include version object file in the final call to the compiler to build the executable because I’ve intentionally not included it in the list of other object files.
That’s it. It works. The build date is updated whenever any other source file is changed. If there are no other changes it leaves the executable alone and doesn’t recompile it unnecessarily.
I think I’m happy, I’ll let you know.
TC
Later...
Friend
Hi there. Been up to much? Have you watched Fallout yet?
No, I’ve been working on my project most of the weekend.
Friend
Yer? What have you been working on?
It’s taken me longer than anticipated getting automatic build dates working.
Friend
Build dates. Doesn’t that just happen?
Not with C. You have to build your own solution it seems.
Friend
Really? Isn’t that just one line of code?
Actually…three…and a bit..
Friend
And that took you all weekend?
Not all weekend. I had to sleep on the problem. Twice. AND then write it up for the blog, that took almost as long.
Excitingly for me, but less so for this blog, I've been doing some actual programming for my day job. It's engaging stuff so I find myself spending longer at work and once I do get home my mind is still busy thinking about it. As a result, I'm not in the mood to work on Tinn and progress…well it stops. However, there have also been days when I've had to wear my manager hat and on those days I am eager to get home and do some programming. So in reality, progress has been made, and I’m overdue for an update.
Code compartmentalisation
I've previously written about the “blog module". The thing is I had not done anything special to separate the code into a module. C has no canonical meaning for “module" but what most people seem to mean is a design pattern using a header file to define a public interface and a C file with the implementation details. This is the pattern I followed, starting with the blog module, then creating modules for the buffer code I'd written, the server code, the client code and so on.
Separating code into modules like this offers a bunch of advantages. Code organisation for one. As the project grows, having the code in separate organised files can make it easier to find the code you are looking for. It can also be helpful when visualising how the program works. You can think at a high level about how the modules interact and then quite separately think about how each individual module works. It also helps avoid name clashes for the implementation details by defining “private" functions as static, this gives them file scope and so can only be seen and used within that implementation file.
It also has some disadvantages, the main one being the compilation processes. Up to now I'd been using the following command to compile Tinn:
gcc -o build/tinn src/tinn.c
After breaking the code into modules, I now need to list every source file:
It's cumbersome to type and it is going to keep growing as I add modules. I could write a shell script, but there are tools out there already for this. Namely GNU Make.
Make is a tool used to manage and automate builds, you populate a makefile that describes how to build your program and then let Make do the work. Out of the box it has some features that elevates it above a simple shell script, for example it only builds files it needs to. If a file has not been modified since it was last compiled, Make skips over that part of the build, reusing what it can and speeding up the whole process.
I'd been avoiding using Make because setting up the makefile was something additional I needed to learn. Eventually I decided to stop procrastinating and jump in. I read https://makefiletutorial.com and created a makefile using their cookbook for inspiration, which in turn was based on a blog post by Job Vranish.
# config
TARGET := tinn
RUN_ARGS := ../moohar/www
COMP_ARGS := -Wall -Wextra -std=c17 -pedantic
# dirs
BUILD := ./build
SRC := ./src
# build list of source files
SRCS := $(shell find $(SRC) -name "*.c")
# turn source file names into object file names
OBJS := $(SRCS:$(SRC)/%=$(BUILD)/tmp/%)
OBJS := $(OBJS:.c=.o)
# and dependacy file names
DEPS := $(OBJS:.o=.d)
# build list of sub directories in src
INC := $(shell find $(SRC) -type d)
INC_ARGS := $(addprefix -I,$(INC))
# short cuts
.PHONY: build run trace clean
build: $(BUILD)/$(TARGET)
run: build
@$(BUILD)/$(TARGET) $(RUN_ARGS)
trace: build
@$(BUILD)/$(TARGET) -v $(RUN_ARGS)
clean:
@rm -r $(BUILD)
# link .o objects into an executible
$(BUILD)/$(TARGET): $(OBJS)
@$(CC) $(COMP_ARGS) $(OBJS) -o $@
# complile .c source into .o object files
$(BUILD)/tmp/%.o: $(SRC)/%.c
@mkdir -p $(dir $@)
@$(CC) $(COMP_ARGS) -MMD -MP $(INC_ARGS) -c $< -o $@
# includes the .d makefiles we made when compiling .c source files
-include $(DEPS)
This is a generic makefile that should work for most C projects and I shouldn't really need to touch it again. I imagine therefore that while I currently have a good handle on makefiles, I will now slowly forget the details of how they work.
Console logging
While moving everything to modules, I took the time to improve the server’s logging and created a console module. This allows me to log things at five different levels. I went with trace, debug, info, warning and error. I then replaced all the various calls to print functions with calls to log to the console.
Why? Well it means I can provide some standard formatting, like prefixing the time to console output. It also sets me up for future enhancements. Currently all console output is just sent to the terminal (technically stdout and stderr). When I decide to send console output to a file as well, I now have a central place to do that.
Command line arguments
I set the default log output level to debug. This means that any trace logging gets silently ignored. I obviously wanted a way to change that setting for when I wanted to see the trace output, and preferably without recompiling the code. So I updated how the command line arguments work for Tinn. Now you can pass an additional -v argument which switches the program into verbose mode, aka enables trace output.
While I was there, I changed the other command line arguments too. Now the port and the content directory are optional, defaulting to 8080 and the current directory when not supplied.
I used some preprocessor macros for each of the logging levels. I'd been avoiding macros up to this point for anything other than very simple constants because again it was something additional to learn. But, I'm not going to learn by avoiding the problem so I experimented. I flip flopped a bit with my approach. At one point the whole console module was basically marcos. Today, it consists of a mostly normal C function (console) with a number of parameters to control output and a number of macros to call that function with some convenient defaults, one macro for each logging level.
Arguably I could have achieved the same result with normal functions. I believe if I declared them as inline the end result after compilation would be indistinguishable. Some guidance I've read online suggests to do just that and avoid macros as much as possible.
The guidance online actually seems to span a wide range of opinions. On one end the advice is to avoid macros because technically they are manipulating the code and it is not always clear what the macro is doing or even when you are using a macro. This can lead to some hard to diagnose bugs. On the other end are people using macros to build some impressive things, like pseudo generics. I'm leaning towards the former opinion for now but will stick with the macros I've created so far to see what, if any, problems crop up.
Colours
To make it easier to distinguish the levels of the console output, I decided to add a splash of colour. Errors are red, warnings orange etc. This is achieved in the terminal with escape code sequences, for example outputting \x1B[31m changes the terminal colour to red and \x1B[0m resets the colour (and anything else changed).
While these codes look initially confusing they do have a pattern. They start with the escape character, the unprintable character you get when you press the [ESC] key at the top left of the keyboard. I’m assuming that's why they are called escape code sequences, they start with an escape. I think I first saw an escape code 26 years ago, today is the first time I’ve realised why they have that name. Anyway, the escape character is number 27 (in decimal) on the ASCII table, which is 33 in octal or 1B in hexadecimal. This is why in code you see escape sequences start with \033 or \x1B, that is how you “print" an escape.
This is then followed by an opening square bracket [. Together, \x1B[ is known as the CSI, which is not just a series of hit TV shows but also the Control Sequence Introducer. Next there is a bunch of parameter data made up of mostly numbers and then a single (normally) letter character which signifies the type of escape sequence. Escape sequences that end with an m are called SGR or Select Graphic Rendition, which lets us set display attributes, like colour. The parameter 31 will for example change the foreground colour to red. Putting all this together gives us the complete sequence \x1B[31m for switching the terminal to red.
The wiki article on ANSI escape sequences lists all the display attributes you can manipulate, including the colours.
Errors
Next I reviewed my error handling strategy and made some adjustments. I’ve classified errors into two broad groups: errors I can recover from and errors I can't. For example, I should expect and recover from errors while reading a request from a client. On the flip side, in most cases I've got no idea how to handle a failure to allocate memory. I need the memory and if I can't get it instead of trying to limp on it is probably safer to end the program.
To assist in this strategy I created an additional logging level, panic, and the appropriate macro which will first log the error message and then exit the program. In addition to being convenient, it means that if I decide to re-review this strategy to make the program more robust, I can search for all the places the PANIC macro is used.
I then took this one step further and created a new utility function allocate. This is essentially a wrapper for a call to realloc with a check for errors that makes a call to the PANIC macro if anything went wrong. It’s a small function, but really tidies up the rest of my code whenever I allocate memory, I don’t need to keep repeating the error handling and I can assume the allocation either worked or the program terminated.
Memory management
In my last post I cited a problem with how routes store paths, specifically how they manage the memory for the path. When the server responds to a client, it maps the incoming requested path to a resource on the server to respond with. This map is stored as a linked list of possible routes. The path in each route is simply a character pointer aka a pointer to a string. The route list code makes sure to allocate memory for each route node as it is added to the linked list and to free that memory if the list is discarded. However it takes no responsibility for allocating the memory for whatever the path pointer points to.
The routes_add_static function scans the content directory and creates a route for each file. This function allocates the memory for each path, stores that memory location in the route’s path pointer and then with its job done, the function ends. The problem being, no code would ever release that memory.
This isn't really a problem because in the program's lifetime the static routes are computed once, near the start of the program, and then required until the program ends. So it didn’t jump out at me as something I needed to rethink.
When coding the blog module I made a mistake which did highlight the issue. The blog_build function generates a page for each post and adds a new route for that post. The paths for each post are computed based on its name as defined in the posts file and stored in the posts_list structure which is created when reading the posts file. Once the blog_build function has done its work, the program no longer needs the posts list and so at the end of the function the posts list is cleaned up and all the memory it had allocated is freed. This is a problem because the paths in the routes list are still pointing at some of that memory.
One solution would be to have the blog_build function allocate new memory for each path and copy the value from the post list to that new string. The routes list would point to that newly allocated memory and it would be left alone forever. This is very similar to how the routes_add_static function works.
I couldn’t bring myself to do it though because it felt like I was digging myself a hole to fall into at a later date. For one I’m now allocating memory for the same thing (paths) in two different places. What if I later add a third? Additionally, if I were to update either the static roots or blog code to detect changes to the file system and update the routes list, I would have to remember when removing a route to make sure I also cleaned up the memory used to store the path.
I see this as a problem of ownership. To keep things manageable, whatever bit of code allocates memory should be responsible for cleaning it up later and whenever possible the management of any particular type of data (e.g. paths) should have a single owner. In this example I have two functions allocating memory for paths and neither exists long enough to take responsibility to clean up. It seems sensible to me to move the management of memory for paths to the code already managing the routes list. It’s a single place that can be used for both static files and blog posts, and it sticks around for long enough to clean up when required. So, this is what I did.
The code to add a new route still accepts string for the path but will now allocate its own memory for that path and copies over the value. The routes_free function now loops through all stored routes freeing the memory allocated for the paths before freeing the memory for the list nodes and the list itself. All the memory management for routes is now handled internally and any other code using the routes lists need not worry about it.
This change made the code in routes_add_static far simpler as a big chunk of that code was actually allocating memory for the paths. For the build_blog function, the big change was how the buffer that stores the generated blog page was managed. In a similar pattern to the path, I moved the responsibility of creating and releasing the buffer to the routes list. The routes_new_buf function now creates a new buffer, adds the route for it and returns the new buffer so it can be populated. The routes_free function recognises which routes have buffers and will free them as required.
I did experiment with the Rust programming language a few years ago. Ownership and lifetimes are a big part of Rust’s strategy to achieve safety and avoid this kind of problem. My strategy here is influenced by what I learnt during those experiments. While these checks are not built into the C language or compilers, I believe it still helps to think in these terms. And no, I’m not planning to switch to Rust, I’m having too much fun with C.
Scanner
I've been reading “Crafting Interpreters" by Robert Nystrom, it’s a rather good book on interpreter design and programming languages in general. I'm very much enjoying it. It's going to be really useful when I build a full interpreter for whatever scripting language I decide to support. I'm excited to give it a go.
Unfortunately I started to see every problem as requiring an interpreter and this led me down a bit of a hole with regards to parsing both the posts file and HTTP requests. While I could write a full interpreter to turn a HTTP request into an Abstract Syntax Tree, it would be overly complicated and unnecessary. All I really need at this stage is a simple scanner to tokenize the request for me.
My scanner code consists of two functions, scanner_new which sets up a new scanner by taking a pointer to a string and a maximum length. I did this so I can scan subsets of strings, or strings that are not null terminated. And, scan_token which takes a pointer to the scanner and string of delimiters and returns the next token. A token is defined as a simple structure with two properties, a pointer to the start of the string and its length.
I use this in the blog module to read the post file. In fact I use two scanners, one to read each line and one to break the line into the fields for each post. This code replaces the scanf call I used before. I admit the new code is longer but it has two main advantages which I place a higher value upon, first it doesn’t have any hard coded lengths and second it’s far easier to read and maintain.
I also used the scanner to read the incoming HTTP requests. My previous code, which was a bit of a mess, only read part of the first line of the request. I’m now able to read all the headers. Sort of. I can read the header name and its value, what I’m not doing is parsing that value as there are many different formats for header values. It is at this point I realised I didn’t actually care about any of them, which is odd because this had been my primary goal for this sprint.
Caching
I took a step back and realised beyond all the other improvements I’ve already discussed in this post, the new feature I was actually trying to add was to enable caching. As it stood, every time a client requests a page or resource from the server, it downloads a fresh copy. This is because I’ve done nothing to let the client cache responses and re-use them as appropriate. For example it would make sense for the client to keep and re-use a copy of the shared CSS file that is used on every page and rarely changes.
In my head I convinced myself I needed to read the request headers for caching to work which is why I was so focused on the scanner. Then I realised what I really needed to do was set some response headers, something I could already do. Specifically, I needed to set the Cache-Control header. If I set that to max-age=604800 it would tell the client it could cache the response for 604,800 seconds, AKA a week. I could have and should have implemented that a while ago.
It’s not necessarily the best type of caching though, it’s a little aggressive. If instead I set Cache-Control to no-cache, (confusingly) the server can still cache the response, but it must check each time that the cached version is still up-to-date before using it. Side note: no-cache is often confused with no-store, which is what you would use to prevent the client from keeping any copy of the response.
For no-cache to work the client needs to know when the resource was last modified. This means adding an additional response header, Last-Modified, with that date. Then when the client requests a resource it will include the request the header If-Modified-Since with the date its cached version was last modified. If the server’s version has not been modified since that date, the server can respond with a status code of 304 - Not Modified instead of the resource telling the client to use its cached version.
Which means I didn’t waste a load of time, the server does need to read the request headers. It needs to check for the If-Modified-Since header. I just needed to write a little extra code to convert the incoming header value from its Internet Message Format date to a time_t variable so I could make comparisons.
With that done, I now have a fairly good caching system and a few options open to me on how aggressive I implement that cache. So far I’ve enabled caching on the static files using the no-cache option. This was fairly easy using the file system’s last modified date. I still need to implement it for generated content as I have a minor issue working out what the last modified date should be, but that can wait till next time.
Summary
On reflection, I have made quite a bit of progress. Breaking the code up into modules, learning about Make and makefiles, sorting out the logging, experimenting with macros, reviewing my error strategy, fixing a memory management issue, building a tokenizer and enabling caching. I took a few wrong turns and got bogged down a little but I feel I’m in a good place again, ready to work on the next sprint.
I’ve switched my domain registrar from 123-Reg to Fasthosts. I’ve done this for four reasons:
About 6 months ago 123-Reg messed up an order for me. They accepted the order, took my money and then silently failed to process the request. When I chased I eventually found out their system didn’t support the domain name I had registered. It worked on the front end (and still does) but they can’t process the order. I did get a refund and a vague suggestion they would update the front end to avoid this problem going forwards, but I lost a month going round in a circle trying to get things sorted and I didn't get the domain I was trying to register.
123-Reg have changed how they handle email forwarding for domains. They now require you to also subscribe to their email service. They have also removed the option to set up a catch-all email forwarder. A backwards step.
123-Reg’s control panel has always been a bit cumbersome. They are slowly replacing it with a new version but so far this doesn’t seem to be making things better. The new version, which they admit is incomplete, has basic functionality missing or hidden. The original version has been updated to remove features that have been migrated, so you have to use both at the same time. It’s a bit of a mess and I’m fed up waiting for it to be finished.
123-Reg’s smallest VPS offering is four times the cost of Fasthosts. To be fair it is four times the capacity too, but that is four times more than I need.
It’s a shame, I’ve been using 123-Reg for about 20 years. I want to show them some brand loyalty but they simply no longer have the products or quality I need. It seems as though they are really focused on selling a complete domain + web hosting + email hosting package. I don’t fit into that bracket. I’m not the only one who is looking for alternatives. The email thing in particular has people upset and moving on.
Enter Fasthosts. Provides Domain registration and management. Supports simple email forwarding and a catch-all forwarder. Has a sensible control panel. Offers virtual private servers at the size I need. And has good feedback online. So I switched and so far I’m very happy.
Reviewing my first version of the blog module, the blog_build function is 173 lines long, which bothers me. It definitely smells of a “make it work” version where I’ve just thrown all the code in one function to just get it working. You can take a look if want here. The list of things that bother me are:
The way I’m handling paths seems cumbersome.
There is some code repetition.
The call to fscanf, it’s cryptic and has some hard coded lengths in it.
The way I build the “prev” and “next” navigation at the bottom of each post is overly complicated.
I’m actually reading the post content from the file twice.
In general the function is trying to do too many things.
Building paths
As explained in the blog module post, this really bogged me down. I know what I need to do, but the memory management for strings in C keeps tripping me up. Let’s break it down.
The problem
I need to work out the path for four permanent files, and an additional two for each post. I have to build these paths from two variables and a bunch of constants/literals. The first variable is the location on my machine where all the content files are stored, this is provided as a command line argument and in a variable called base_path. The second is the directory name for each individual post, read from the posts file.
File
How the path is computed
Header fragment 1
base_path + blog_dir + ".header1.html"
Header fragment 2
base_path + blog_dir + ".header2.html"
Footer fragment
base_path + blog_dir + ".footer.html"
Posts file
base_path + blog_dir + ".posts.txt"
Post content
base_path + blog_dir + post_dir + “/.post.html”
server path
blog_dir + post_dir
The first problem is I need to check if the incoming content root has a trailing forward slash or not. As this is specified on the command line, either is possible. When adding this to the rest of the path I don’t want to end up with a double forward slash or no forward slash.
Second problem is that I moved the header and footer files to the blogs directory so 5 of the 6 files all started the same, to make the code a bit easier. I would prefer the HTML fragments were in the root or a common directory so I could use them elsewhere on the site.
Third, I need to make sure I have enough space to build the whole path, but because I don’t know the length of the post directory names yet, I don’t know what this is.
I decided that 256 characters for a directory name was probably more than enough, but to be safe I set this as the constant max_len, intending to use that later to validate the incoming directory name lengths. I also created two constants, one for the blog directory name and one for the content file name so I could change them easily if required.
Then it gets weird. On line 7 I create a variable called bpl which right now I know means “base path length” but in about six months when I’m looking back at the code I won’t have a clue, so I should probably change it. Then on line 8 I create spl aka “server path length”, which is effectively the length of the blog directory name and some forward slashes. Then on lines 9 to 11, I check if the last character of the content root is a forward slash and if it is I reduce the bpl by one because I’ve included the forward slash in the blog directory name.
On line 12 I create a character array called path with enough space for the content root, the blog directory name, 256 characters for the post directory name and then content file name (/.post.html).
Next I copy the content root into my new path. Then add the blog directory name to the path using pointer arithmetic to place it in the correct position. Using the bpl variable I manipulated earlier as an offset means that if the content root had a trailing forward slash, it will get overwritten by the one in the blog directory name, if it didn’t the blog directory name is appended. Either way I won’t end up with just the one forward slash.
Finally, on line 15, I add the length of the blog directory name (and all its forward slashes) to bpl. From this point on path + bpl points to the first character in the path that would be inside the blog directory, and for at least 5 of the paths, that’s the part I want to manipulate. For example to build the path for the the footer fragment I use:
strcpy(path + bpl, ".footer.html");
The path variable will now contain the complete path to the footer fragment file that I can use in a call to fopen (file open). Later when I want to build the path to a post’s content file I would use:
It works. It might even be efficient. But it irks me.
I’ve had a few days to think about this. What bugs me is I’m trying to do too many things all at the same time. Notably, validate the incoming content root and make sure I don’t cause an overflow. I did enter a bit of a loop as some of my ideas to address this would make the code less efficient in terms of memory management. Which touches on a flaw in my simplified software engineering aphorism, sometimes to make it neat you make it less fast, and sometimes to make it fast you have to make it less neat. So to make progress I’m going to focus on making it neat. I'm not completely ignoring speed and efficiency, it's just a secondary concern right now.
Validating the content root
I decided to move the responsibility for validating the content root out of the blog_build function and into its own function that would be called by main when validating the command line arguments in general. That's where it should be really.
I then remembered I can change the current working directory. The library function chdir would accept a path with or without the trailing forward slash and then switch the working directory to that directory. From that point on any other file related functions like fopen using relative paths would start in that directory. More than that, I could test the response of chdir to ensure the path was a valid directory. It’s such an obvious solution I can’t believe it took two days for me to think of it.
int main(int argc, char* argv[]) {
// validate arguments
if (argc != 3) {
fprintf(stderr, "Usage: %s port content_directory\n", argv[0]);
return EXIT_FAILURE;
}
// change working directory to content directory
if (chdir(argv[2]) != 0) {
perror("content_directory");
return EXIT_FAILURE;
}
// build routes
struct routes* routes = routes_new();
blog_build(routes);
// … more code …
return EXIT_SUCCESS;
}
The blog_build function doesn't need to know or care about where the content root is. It now just assumes it’s the current directory. Arguably this is less flexible but I have to remind myself I’m not building a library, this function is only used in this program and only used once. So I can remove flexibility to increase simplicity and readability.
I did think about using chdir within the blog_build function as I load the files from different places, however I decided against it as I wanted the error messages (should a file be missing for example) to have some context, i.e. at least be a path starting at the content root.
Avoiding overflows
I already solved this problem. I created the buffer structure and functions to deal with reading requests and composing responses. I could use the same functions to build a path and let them worry about allocating enough space. But that does seem overkill, so I wanted to explore other options first.
Experiment one was a function called make_path. I was really aiming for ease of use. It is a variadic function that can take a variable number of string arguments. It will then loop through each of them adding them to a single string up to a maximum length and return the result.
I have concerns. While it is more convenient to call than other solutions, the first parameter specifying the number of strings being passed detracts from its convenience. This seems like something the compiler or the va_* variadic library functions should be able to deal with.
More of a concern is the static character array being used to store the resulting path. That is a can of worms right there. Being static, it is a chunk of memory that is going to persist for the entire program run, and considering I’m only using this during the program's start up, it seems like a waste. I know the focus is neatness and not efficiency, but this seems just too inefficient. Also, not that it matters yet, but I think the static variable means it is not thread safe. I get the impression that static variables like globals should be avoided, at least until I understand them better.
Another potential problem is this function will silently truncate the input if the output will exceed the maximum size. The result will be correctly terminated and will not overflow, but there is no way outside the function to detect if the input was too long.
I decided make_path was not the solution. It did however give me an idea, I could use snprintf to build the path.
#define MAX_PATH_LEN 256
void blog_build(struct routes* routes) {
const char blog_dir[] = "blog";
char path[MAX_PATH_LEN];
// …
// build path for post file
snprintf(path, MAX_PATH_LEN, "%s/.posts.txt", blog_dir);
// …
// build path for post content
snprintf(path, MAX_PATH_LEN, "%s/%s/.post.html", blog_dir, post_path);
// … more code …
}
I quite like this. Overflow safe. Reasonably flexible. Not overly complicated, certainly no pointer arithmetic to remember/decode. It’s probably less efficient than my first version, but adequate for what I need and not needlessly wasteful. It is however silently discarding any input that would overflow, but that is because I’m not inspecting the return value.
snprintf returns the number of characters that should have been written to the buffer excluding the null terminator (or a negative number if an error occurs). The second parameter indicates the maximum buffer size including the null terminator, for which I pass MAX_PATH_LEN. So, if the value snprintf returns is equal to or greater than MAX_PATH_LEN, the path got truncated.
int len = snprintf(path, MAX_PATH_LEN, "%s/%s/.post.html", blog_dir, post_path);
if (len < 0 || len >= MAX_PATH_LEN) {
fprintf(stderr, "Error, unable to create path for \"%s\"\n", post_path);
continue;
}
I added this check when building the path for the post content. This is being built based on a value from the posts file which I can't guarantee the length of, so needs the check. Elsewhere, like for the posts file itself, where the length is predictable and I therefore know fits in the buffer, I don’t need to worry about the return from snprintf.
This is not the end of my journey with string manipulation in C. Right now I’m comfortable with it again. It seems to me snprintf is definitely the way to go if you need to do anything more complicated than the most basic copy or concatenation. I'm certain I’ll go to implement something in the coming days or weeks that will cause me to question everything again. For now however, it's time to move on.
Code repetition
Lines 832 to 854 load three files into buffers, these are the three html fragments. It’s clear I wrote this once, copied it, pasted it twice and modified it slightly.
To give myself some credit I did create the buf_append_file function the first time round so a good chunk of the code to load a file is already in an appropriate function. Still, it seems there is still an opportunity to make this neater. First, I moved the fragment files back to the content root, with the other changes I already made, this removed the need to construct a path for each file, I could just use a string literal. I then created a buf_new_file function that creates a new buffer, loads it up with a file, reports with any errors and returns a pointer to the new buffer.
Much neater. BUT, I’ve created a problem. What happens if one of the files fails to load? Before I would print an error and escape out of the blog_build, not great but at least the code would not crash. Now the error still gets printed but the buf_new_file function will return a NULL pointer and the blog_build function will carry on regardless until it tries to use that buffer, and then crashes.
Error reading .footer.html
fish: Job 1, 'build/tinn 8080 ../moohar/' terminated by signal SIGSEGV (Address boundary error)
I need to check if the returning buffer is not NULL. If I do it for each file in turn, the resulting code would not be much neater than the original. I could instead check all three after loading them.
Something I forgot to do in the previous code if there was an error, was to tidy-up and free any buffers that did get created. For this to work I needed to make a small change to the buf_free function to check for and ignore NULL pointers. I also changed the blog_build function to return a boolean indicating if it was successful. This way the main function can check the result and handle it appropriately.
If there were more than three files, I would be looking to use an array and a loop, for now though using three separate variables is probably less work than setting up an array.
Reading the posts list
The original version of the blog module would read the posts file one line at a time, interpret that line, try to do everything with that post in one go and then move on to the next post. One issue here is to build the navigation at the bottom of individual posts, I at least need to know the path of the next and previous posts. The current code deals with this by not computing the navigation until it’s read the next post. As a result each iteration of the loop is actually dealing with two posts, the navigation for one and the content for another. This is why there are variables like next_post_path and next_next_post_path. Some of the code is also duplicated outside the loop to close off the last post. Dealing with edge cases, like the first and last post, also requires nested checks which is duplicated in and outside the loop. It’s not clean.
The plan is therefore to break this down into at least two phases. First read the post file and convert it into an array that can be accessed randomly (as opposed to sequentially). Second, use the array to build each post (and the archive page (and the home page)) in a slightly clearer and sane way.
This started by defining a new struct to hold the information about each post.
Then because I want the array to resize as required I copied the list code I’ve used a few times and modified it to work with the new post structure. My brain is screaming at me that there should be a generic way to handle these dynamic arrays. I know it’s not straightforward in C so I’m filling that in the “later” pile.
I created the function blog_read_posts which reads the posts file and for each one creates a posts entry using the above structure. This includes reading the content from the .post.html file for each post into the buffer.
This code is still using an fscanf call to parse each line in the posts file.
I’m going to leave this line alone for now. It still bothers me that there are hardcoded limits for each field. I did this to prevent overflow, but the value (255) is not automatically linked to the MAX_PATH_LEN defined elsewhere. If I change one, I will have to remember to change the other. A bad idea. Also while I understand the format string today, it’s really hard to read and would be a pain to update at a later date. I will revisit this code when I work on parsing the incoming HTTP request headers, it’s a similar problem.
The way I maintain the list is slightly different from other list examples. I start with a call to posts_list_draft which ensures there is enough space for a new entry in the list and then returns a pointer to that new entry. The key difference is that it does not update its internal count. In effect, the new entry is not yet “committed” to the list. If you were to loop through entries using the count to determine the upper bound, it would not include this new entry. I then use this new entry to capture the results of the fscanf call and load the contents buffer. If everything works I call posts_list_commit which simply increments the count by 1, effectively committing the new entry. If anything goes wrong I don’t commit and a subsequent call to posts_list_draft will return a pointer to the same entry as before that can be overwritten.
Back in the blog_build function I can now loop through the array of posts to create the required pages. To keep things clear I actually loop through the posts three times. Once to create the individual pages, once to build the archive page with a link to each post, and one last time to build the home page with all the posts in a single page. Because I can now look forwards and backwards in the array, building the navigation is far simpler, there is no longer a need to overlap the creation of the pages and have variables like next_next_post_path.
The code is still verbose, but it is at least now easy to follow.
The verboseness comes from having to add the strings to the buffer one at a time. My recent experience with snprintf caused me to consider if there was a better way. I already have a buf_append_format function that uses vsnprintf (the variadic version of snprintf), but I’d not quite got it’s implementation correct as I required the caller to pass a maximum size of the formatted string. This is inconvenient and not in the spirit of the buffer which should just expand as required. Now I understand how to use the return value from snprintf I could update the code to not require that parameter.
long buf_append_format(struct buffer* buf, char* format, ...) {
long max = buf->size - buf->length;
va_list args;
va_start(args, format);
long len = vsnprintf(buf->data + buf->length, max, format, args);
va_end(args);
if (len >= max) {
if (!buf_ensure(buf, len+1)) {
return -1;
}
va_start(args, format);
len = vsnprintf(buf->data + buf->length, len+1, format, args);
va_end(args);
}
if (len < 0) {
return -1;
}
buf->length += len;
return buf->length;
}
Essentially the code now attempts to append the formatted string to the buffer and if the required space is more than was available it expands the buffer and tries again. This means I can tidy up the code to create a post page a little more.
// build blog pages
for (int i=0; i<posts->count; i++) {
struct buffer* post = buf_new(10240);
buf_append_buf(post, header1);
buf_append_format(post, " - %s", posts->data[i].title);
buf_append_buf(post, header2);
buf_append_format(post, "<article><h1>%s</h1><h2>%s</h2>\n", posts->data[i].title, posts->data[i].date);
buf_append_buf(post, posts->data[i].content);
buf_append_str(post, "<nav>");
if (i < posts->count-1) {
buf_append_format(post, "<a href=\"%s\">prev</a>", posts->data[i+1].path);
} else {
buf_append_str(post, "<span> </span>");
}
if (i > 0) {
buf_append_format(post, "<a href=\"%s\">next</a>", posts->data[i-1].path);
}
buf_append_str(post, "</nav></article>\n");
buf_append_buf(post, footer);
routes_add(routes, RT_BUFFER, posts->data[i].server_path, post);
}
Not a huge saving in the number of lines, but it does help with clarity. For example, the code to add the “next” link is now a single line with an obvious intent instead of spread over three.
Review
Let’s review my gripe list.
The way I’m handling paths seems cumbersome. -> This has been mostly replaced with calls to standard library functions, specifically chrdir and snprintf. It's no longer cumbersome, it's actually quite neat.
There is some code repetition. -> The obvious examples have been replaced with functions. I think there is potential for some code reuse with how the page content is being generated, but it's not as simple as it first looks. There are enough differences between the page types that a quick function is not going to cut it. I'll think about this some more.
The call to fscanf, it’s cryptic and has some hard coded lengths in it. -> This has yet to be addressed.
The way I build the “prev” and “next” navigation at the bottom of each post is overly complicated. -> Breaking the code into two phases, reading the data into an array and then using the array to build the pages has made building the navigation trivial.
I’m actually reading the post content from the file twice. -> The same array used for the previous point also solved this problem.
In general the function is trying to do too many things. -> The blog_build function is now 94 lines long and most of that is the actual composing of content. The rest has been moved to appropriate functions.
At this point the code is better organised, more readable and easier to understand. Therefore it is more maintainable. Goal achieved. This has for example enabled me to spot some bugs, especially around handling potential errors which means I now have a more robust solution. In addition my change in approach let me add the following new feature with ease.
Blogs are backwards
I’ve always felt that blogs are backwards. I know why they are the way they are. You want your newest content at the top for lots of reasons. But I’ve always felt there should be an option to read the blog in chronological order. Sometimes when you discover a new blog and want to read it in its entirety, it would be helpful to do this from start to finish without any unnecessary navigating and/or scrolling back and forth. So I added a way to do that on my blog. I added the log page.
To generate this page I simply loop through the posts array in reverse order. Job done.
Outstanding issues
I need to review the code around the routes list. In my recent testing I encountered a memory management problem with how the paths are stored in the routing list and what bit of code should be responsible for that memory. I’ll think I’ll address that next but this post is getting too long already. For now I’m not freeing up the posts array after I’ve built the post pages, which ideally I should be able to do.
I also need to review my error handling strategy, it’s inconsistent at the moment with how I return an error, where the responsibility for reporting the error is, and how to free up resources already allocated.
My code is now over a thousand lines. It’s past time to move to multiple source files. I’ve been avoiding that because that also means I should probably learn about makefiles. Or is it build files? I’m sure I’m about to find out.
Finally, I know the home page and my new log page are going to grow to a size I shouldn’t load them in one go. I need to implement some infinite scrolling mechanism that loads posts as needed, and that means JavaScript. Which is exciting.
I have recently been expanding my collection of botanical LEGO sets. Technically my first botanical LEGO set was the tree house which I got back in 2020. I think its inclusion in the botanical section of the shop is a retrospective thing. It’s one of my favourite sets and has been sitting on top of a pedestal next to my desk since I built it in May 2020. Yes, it needs dusting.
A new-years tradition for me is to treat myself to a new LEGO set and spend new-years eve half listening to the festivities on the TV while building that new set. This year it was the Super Mario Piranha Plant. Not actually part of the botanical collection, but I think it should be. It’s a cool set, and actually fits on my desk. I’m detecting a recent trend with LEGO releasing sets for adults which are of a more reasonable size, which is good because we can then display them somewhere. I hope they keep it up.
In January I purchased the LEGO Bonsai Tree. I’ve been considering this set for years, but it never made it to the top of my shopping list, until the piranha plant caused it to jump. Besides I had a birthday coming up and…I’m an adult I don’t need an excuse. I built it last month and plonked it in front of my monitor. It added some much needed colour to that part of the desk, but there was room for more, soooo, I purchased the LEGO Succulents and today I built them.
There is still room for more. I have my eye on the Tiny Plants. What I would really like to do is build a whole LEGO garden that hides/manages all the cables with a back that comes up to the height of the bottom of the monitor. I’m not sure where to start with that. I might take a look at bricklink, I think they have some design software I could play with. Don't panic, it's just an idle thought, Tinn is still my priority.
Something I often tell my team and have to keep reminding myself is it takes three attempts to write good code.
You (should) know what the desired outcome is from the beginning, but you don’t necessarily know how to achieve it. Even if you think you know, you don’t really understand the underlying problem until you actually start writing code. Attempt one is experimental. It's a stream of ideas collected from past experience, Google searches and (for us old people) books. The various chunks of code are held together with sticky tape and good wishes. As you start testing and encounter unexpected issues you patch the code with more code in an increasingly desperate and exacerbated attempt to fix all the holes in your logic. The only goal is to get it returning the correct result without the computer crashing. This is the “make it work” phase.
It’s at this point you now understand the problem. Not only are you getting the output you want, but you know the steps required to get there and all the difficulties and obstacles that you might encounter along the way. You also have at least one solution to study and review. You can now look for patterns. You can use hindsight to avoid issues and make better decisions. Attempt two is about correcting mistakes and making it clean and presentable. The goal is to make a version you can be proud of and would be happy to share with others. It’s also very important you don’t break it in the process. This is the “make is neat” phase.
Now you really understand the problem. You’ve made two versions already and explored it from two different angles. By this point you’ve tested it hundreds, maybe even thousands of times. With any luck it’s been tested at scale too. You start to spot the bottlenecks and inefficiencies. You become confident where shortcuts can be taken and importantly where they must be avoided. A third version starts to form in your mind, a leaner, faster, more efficient version. The goal is perfection. This is the “make is fast” phase.
It’s not an original take on software development. A quick google search shows I must have read it somewhere before because it’s everywhere. Nothing is original any more. Anyway, Kent Beck is credited with the quote “Make it work, make it right, make it fast”. I also found a reference to an article by Stephen C. Johnson and Brian W. Kernighan (yes that Brian) in the August 1983 edition of Byte magazine with the quote ”But the strategy is definitely: first make it work, then make it right, and, finally, make it fast.” So it’s almost as old as me. My version is neater though.
I don’t believe it’s exclusive to software engineering. I'm sure other professions have variations of this iterative approach. For example in film editing, they go through various stages: initial assembly; rough cut; final cut; directors cut. I’m sure writers have a system too. I should probably research what the suggested stages are for writing blog posts. Even my journey to become physically fitter is going through stages of increased understanding. The outcome has never changed but as I try more things I slowly begin to understand what the actual problem is.
The point, which I keep having to remind myself, is we very rarely get things perfect the first time. If we aim for perfection on the first attempt, we are setting ourselves up for failure. In many cases, aiming for perfection from the beginning can cause a kind of paralysis that prevents us from making any progress. The “make it work, make it neat, make it fast” aphorism gives us (well me at least) permission to focus on the important parts in the correct order and make progress.
Obviously there are subtleties, not every bit of code needs to go through three versions. Some need to go through many more iterations to get them right. It can also be nested, where the various modules of the program go through each phase as does the whole program.
The risk is that due to real world time pressures we never get a chance to go through the “make it neat” or “make it fast” phase. I see this a lot. Most of the work my team has developed and deployed only had time to go through the first phase. Which means the work delivered from the “make it work” phase, still needs to be neat enough to be maintainable and still needs to be efficient enough it doesn't take too long to execute or set the CPU on fire.
The reality is the code we deliver has gone through a few cycles but often there is a bunch of outstanding work we know that could be done to make it neater and or faster. We just don’t have time. Also “code something, test it, fix it, make it do more things, test it, fix it, test it, make it neater, test it, fix it, test it, make it faster, test it, fix it, test it, test it more, fix it, test it, panic, roll back, deploy, run away, come back later” is not as concise as I would like. Might make a cool dance track though.
Now I’ve got that out of my head, I can return to the blog module and resume with phase two “make it neat”.
I decided to write a blog module. Nothing fancy, just some code that helps with the common header and footer for each post and consolidates them for the home page.
I’ve been avoiding writing this code for a bit. My intention was to build a fairly complete (but basic) web server first, and this falls outside of that scope. In the big picture of this project I see the blog as an application that would be hosted by an application server. I’m not there yet. However, I’m fed up with copying each post to three different places, so time for a quick diversion to write some code that generates blog pages.
I started with an update to the routes list adding a new type RT_BUFFER. I updated the route structure, changing the to member form a char* to a void*. Where before it could only point to a string, it can now point to anything.
Next I updated the client_read function so when routing the request it recognises the new RT_BUFFER type and makes a call to client_prep_buffer a new function that reads it’s content from the buffer in the route instead of a file as I had done previously.
To test this all worked I created a buffer with a simple ”hello, world!” message and added it to the list of routes.
In all it took about 10 minutes to plan, make and test the change and it all worked lovely which naturally made me suspicious. I moved forwards anyway.
I then created a file in the blog directory called .posts.txt. The leading . would mean my other routing code would ignore the file. This file would contain a list of blog posts in order, one per line. Each line would contain three fields, tab (\t) separated: the path; the title and the date.
I also created three new files .header1.html, .header2.html and .footer.html that contained fragments of HTML I would use building the pages. The plan was to then loop through the posts file and for each post, create a buffer with the page content and add it to the list of routes. This is where I figuratively ran into quicksand and my progress slowed wwwwwwaaaayyyy down.
The issue was dealing with paths. I needed to compute lots of similar paths. One for each of the three HTML fragment files, one for the posts file and then for each post one for the path of where the content was and one server path that should route to that page. I basically required a bunch of string manipulation which, as I’ve touched on before, works at a different level compared to my normal programming experience. Making sure I validated the input strings from the command line and posts file and ensured I had enough space for the concatenated path required some mental gymnastics I wasn’t ready for.
I got there in the end, but the resulting code is a mess. This was definitely an example of “make it work” and it does seem to work. I think my approach is sound. I need to review how I’m managing those paths and either convince myself that this is the correct way for C or find a cleaner way to do the same thing.
What started as a quick diversion to cut down on some admin has kicked over that can of worms that I never really completely tidied up last time. I really want to get stuck in right now, but it’s late and I have a day job.
I tested serving up files that are about 10 megabytes in size. While it worked, it made the server very unstable and became a problem if the server received multiple requests at the same time. I also tested serving an MP3 file. This almost always blocked the server from other requests and if I navigated away or cancelled before the MP3 finished downloading, the server would crash.
When calling send to send data to the client, there is no guarantee it will send all the data you've asked it to send. Thankfully the function will return how much data it did send, so you can react appropriately. Up to now I've been using some code which repeatedly calls send keeping track of what actually gets sent until all the data is gone.
void send_all(int sock, char *buf, size_t len) {
size_t total = 0;
int sent;
while (total < len) {
sent = send(sock, buf+total, len-total, 0);
if (sent == -1) {
fprintf(stderr, "send error: %s", strerror(errno));
return;
}
total += sent;
}
}
This is a bit like foie gras, force-feeding the client all the bytes if it wants them or not. Not a good idea. This is also the code that is blocking the server because if the client is not ready to receive the data, send will just wait until it is, ignoring everything else.
To make the code more client friendly, only sending the client data when it is ready, I needed to ditch my send_all function and instead use polling to detect when the client socket is ready to receive data.
First I moved the output buffer to the client_state structure. This way each socket would have its own output buffer that would persist over multiple iterations of the main network loop, a requirement if I'm not sending all the data in one go. I also updated the buffer so it contains a read pointer to keep track of how much of the buffer has been read and sent. I was in two minds about if this should be a feature of the buffer or something to store in the client_state directly. I went with the buffer for now.
Second I wrote a new function called client_write to handle sending data to the client. This makes a call to send but with an additional MSG_DONTWAIT flag instructing it to not block if it can’t send data. If the send function sends less data than available, the code changes the poll file descriptor for this socket to wait for a POLLOUT event. This is triggered when the socket is ready to receive data without blocking. If all the data is sent, it sets the events list back to POLLIN to wait for the next request.
int client_write(struct pollfd* pfd, struct client_state* state) {
long len = buf_read_max(state->out);
long sent = send(pfd->fd, buf_read_ptr(state->out), len, MSG_DONTWAIT);
if (sent < 0) {
fprintf(stderr, "send error from %s (%d): %s\n", state->address, pfd->fd, strerror(errno));
return -1;
}
if (sent < len) {
buf_seek(state->out, sent);
pfd->events = POLLOUT;
} else {
buf_reset(state->out);
pfd->events = POLLIN;
}
return sent;
}
I created the equivalent client_read function and moved most of the code from the client_listener function to it. I tweaked the code that prepares the response so it just populates the output buffer but doesn't try to send it yet. That is left to the client_write function.
Finally I updated the client_listener function to check the incoming events and direct the code to the appropriate read or write function.
void client_listener(struct sockets_list* sockets, int index, struct routes* routes) {
struct pollfd* pfd = &sockets->pollfds[index];
struct client_state* state = sockets->states[index];
int flag = 0;
if (pfd->revents & POLLIN) {
flag = client_read(pfd, state, routes);
} else if (pfd->revents & POLLOUT) {
flag = client_write(pfd, state);
}
if (flag < 0) {
close(pfd->fd);
client_state_free(state);
sockets_list_rm(sockets, index);
}
}
This fixed one of my problems. The server was no longer blocked when one client was downloading large files. Two clients could now happily query the server at the same time. Happy days.
However the server still crashed if I cancelled a download. This is because I wasn't handling hang-ups correctly. I thought I had dealt with this in the read code. If a call to recv reads zero bytes I interpret this as the client closing the connection, which is true. It is however possible for the client to close the connection at other times, like when I’m trying to send data to it. It's easy enough to detect this by checking for a POLLHUP event, which I was not doing.
I updated the client_listener code to first check for POLLHUP events before trying to send it data. While I was there I also got it to look for the other error events POLLERR and POLLNVAL. In all three cases it now closes the socket nicely instead of crashing instantly. Super happy days.
void client_listener(struct sockets_list* sockets, int index, struct routes* routes) {
struct pollfd* pfd = &sockets->pollfds[index];
struct client_state* state = sockets->states[index];
int flag = 0;
if (pfd->revents & POLLHUP) {
tprintf("connection from %s (%d) hung up\n", state->address, pfd->fd);
flag = -1;
} else if (pfd->revents & (POLLERR | POLLNVAL)) {
fprintf(stderr, "Socket error from %s (%d): %d\n", state->address, pfd->fd, pfd->revents);
flag = -1;
} else {
if (pfd->revents & POLLIN) {
flag = client_read(pfd, state, routes);
} else if (pfd->revents & POLLOUT) {
flag = client_write(pfd, state);
}
}
if (flag < 0) {
close(pfd->fd);
client_state_free(state);
sockets_list_rm(sockets, index);
}
}
The server seems much more stable now. Before it would crash every so often after getting a request from random crawlers looking for an admin page or something. It would seem these requests will hang-up when they don't get what they were looking for because now I'm handling hang-ups, they don't seem to crash the server anymore. Another thing fixed. I wonder what will be next?
I had to make a fix to the routing, specifically I hadn't considered URLs that contained parameters. Parameters are the part of the URL after the question mark. The bit before the question mark identifies the resource you are looking for, the parameters are extra options you can pass to the server to do magic things with that resource.
I was re-hosting an old project that uses parameters (more on this later) and the server was attempting to map the entire incoming URL including the parameters to a file, this obviously failed.
The fix was quite simple, I used the strchr function to return a pointer to the first instance of the ? character, then using some pointer magic I replaced the question mark with a null terminator. This effectively means if I treat the path variable as an array, It now contains both the path and the query, if I treat it as a string it now only contains the path. I think this is a valid approach, but it feels a little wrong.
I was worried initially that when the path array is freed, it would only free up memory to the null terminator I added. I realise this is not a valid concern, this is not how memory management works. If the array is on the stack, when the function exits, the whole stack frame is released including the entire array. If I allocated it on the heap using malloc, a call to free releases all the memory allocated no matter what I’ve done with the data in it.
Having slept on it, I’m fairly confident this is in fact an efficient way of parsing the URL. It may also be a good approach to parsing the entire incoming request. It’s a destructive approach. By interesting null terminators at key points to break up the request into individual strings I would not be able to treat the whole thing as a single string again. I think this would be OK, an approach to keep in mind.
Getting back to the URL for a second, parameters are not the only thing I need to worry about, URLs can also have anchors, which is everything after the hash (#) character. The same approach works here too.
Directories
I also changed the way I route requests for directories. Previously if the URL mapped to a directory I would look for and serve the index.html from that directory. This is fairly standard behaviour. It gets complicated because you can have two different paths for the same directory. For example, /foo/bar and /foo/bar/ both map to the same “bar” directory. One has a trailing /, the other doesn’t.
Technically there is nothing stopping you from returning different content for each of the URLs, but that is considered confusing and bad practice. So I want to treat them the same.
I had catered for this by serving the index.html file (if present) in both cases. The problem is with relative urls. When responding to the /foo/bar path, the current directory is considered to be the “foo” directory. When responding to /foo/bar/ the current directory is considered to be the “bar” directory. If the index.html file contains relative URLs for other resources, those URLs will point to different places in the two different scenarios. The correction I've made is when the client requests a directory without a trailing forward slash, I respond with the HTTP code “301 - Moved Permanently” to redirect the client to the URL with the forward slash.
Except not in all cases. At the moment all the content on this site is stored in static files. That includes the blog posts which are in plan boring HTML files. At some point this will change and I will move the posts into a database. Each of these posts also has a direct link and thinking forwards I do not want the link to change when I move them into the DB. So I’ve added some hackery to the routing code for individual blog posts. For example the path for this post is /blog/routing but the HTML is currently in the file /blog/routing/post.html and any other resources like images will also be stored in the directory /blog/routing/. It works for now, but at some point when I have a proper blog module/app, I’ll need to revisit how routing works.
Colour
I also added some colour. The blog looks much better now, well at least I think so.
I'm not particularly skilled at web design. I can tell when something is working and when it's not, but when it's not I don't exactly know what to do to fix it, I get there by trial and error. It's going to be an iterative process.
At some point I need to add a masthead, but right now I'm not sure what that will look like. I did briefly have a play with DALL-E in an attempt to make a logo for the site. It generated this, which is far too busy for a logo and makes me out to be far cooler than I really am.
I read the HTTP spec. Well I read most of it. It’s not an exciting document and there are parts of it where my brain wandered off. I am fairly certain I didn't miss anything important. If you are struggling to sleep at night, you can check out RFC 9110 the international standard for HTTP for yourself.
I can’t on the surface see what I’m doing wrong, my understanding of HTTP was broadly correct. There are a few response headers marked with a SHOULD that I’m not currently including, notably Date, but these shouldn’t cause the problems I’m seeing. I added the Date header anyway to be sure it didn’t fix the problem, and it didn’t.
One thing I was doing incorrectly, was only using a new line feed (\n) as a line separator in my responses, this should be a carriage return and a line feed (\r\n). I actually corrected this several days ago and forgot to mention it, but it also didn’t fix the problem. As it happens the browsers seemed quite happy with just line feeds, I assume there is some tolerance built in but it is better that I follow the standards.
I was starting to think that the problem is not with how I’m formatting the response but how I’m handling multiple sockets and/or multiple requests. The problem with Chrome failing to complete a request only seems to occur when there are multiple resources to load, for example the HTML and an image. Maybe it is using that second socket it opens but I’m sending my response to the wrong place. Maybe this is why the request never seems to finish as the socket Chrome is waiting on never gets any data.
I’m not sure if it’s because I was re-using the same two buffers for reading the request and composing the response for all sockets. I assumed this would be ok because my program is single threaded so I’m dealing with each socket in turn. In my head I read the request, parse it, compose a response and send it in a single sequence, so the buffers are then available to be re-used for the next socket in the list. It’s possible I messed up the way I’m re-using the buffers. It's also possible that I’ve misunderstood how sockets work and while I’ve finished with the buffers, under the covers the socket has not. Or I could have just made an error in logic somewhere.
Whatever the reason, I decided I needed to take a step back, review the basics of how strings, arrays, pointers and memory works in C. Then review all the code up to this point with a better, more informed understanding of how everything should work.
Back to basics
Strings
I know how strings work in C, I’ve learnt it a few times, but when you don’t use it every day and spend most of your life working with languages that deal with strings in a different way, you forget the subtleties. Also when you go and build a dynamic list of strings and end up with a pointer to a pointer (to another pointer?) and you're not used to the syntax, your brain is at risk of melting. So I wrote a couple of test programs to mess around and remind myself how it all works.
I know a string is just an array of characters followed by a null terminator (aka a byte set to zero). This means you need to make sure you have enough space for the characters and one extra byte for the null terminator. It is particularly important because when you pass a string to a function, what you are actually doing is passing a pointer to the first character, that function will then keep stepping through memory until it finds that null terminator. Create an array of characters without that null terminator and pass it to a function that is expecting one and you have an overflow, the cause of many bugs and security exploits.
I wrote some code to see an overflow in the wild, run on your computer at your own risk.
char hello[5] = "hello"; // force a non-terminated array of characters
char world[] = "world";
printf("hello size:%d\n", sizeof(hello)); // 5
printf("world size:%d\n", sizeof(world)); // 6, the 5 characters and the null terminator
printf("hello strlen:%d\n", strlen(hello)); // undefined behaviour
// probably 10 as it overflows into world
printf("world strlen:%d\n", strlen(world)); // 5
printf("%s %s\n", hello, world); // undefined behaviour, probably "helloworld world"
Alternatively, for some functions you need to tell the function how many characters (or bytes) to process. For example the send function takes a pointer to any buffer and the number of bytes to read from it. In reality the send function knows nothing and cares not about strings, it just sees bytes. Some functions do both, for example strnlen will look for the null terminator, but over a maximum of n bytes. Most of the str* functions have a strn* variant so you can make overflow safe code.
Returning Strings
Returning a string from a function is also a pain in the backside. It is a problem with memory management and how when returning a value from a function, the system is actually copying the value from one stack frame to another. This is not a problem for scaler variables that have a known size and are generally small. With strings of varying sizes, it becomes an issue.
Generally speaking there are two solutions. Don’t store the string on the stack and instead use the heap, the function can then return a pointer to the string on the heap. The problem here is the callee has to remember to free the memory when it’s done with the string, easily missed and/or forgotten. The second option is for the callee to create a buffer in its stack frame with enough space for the string and then pass a pointer to the buffer to the function. The problem here is you have to make an educated guess on how much space to allocate and code defensively or end up with a buffer overflow.
I will probably use a combination of the two approaches, picking the appropriate one depending on the circumstances. It’s not a big issue, just something I have to be careful of because after years of coding in JavaScript and LotusScript my default thinking is invalid. For example, I wanted to create a function that generated a time stamp as a string to use in my logging. I started with the following code to test my understanding of the time functions.
src/test.c: In function ‘time_stamp’:
src/test.c:17:16: warning: function returns address of local variable [-Wreturn-local-addr]
17 | return rv;
| ^~
I then realised what I had done. The rv (return value) is allocated in the function’s stack frame and will be unallocated when the function returns. So the pointer I’m returning will point to an invalid location before I get a chance to use it in the calling function. The compiler caught it and warned me. Thank you compiler. The correction is to pass a pointer to a buffer allocated higher up (or is that lower down) the stack.
#include <stdio.h>
#include <time.h>
char* time_stamp(char* buf, size_t buf_size) {
time_t seconds = time(NULL);
struct tm* gmt = gmtime(&seconds);
//snprintf(buf, buf_size, "%02d:%02d:%02d", gmt->tm_hour, gmt->tm_min, gmt->tm_sec);
strftime(buf, buf_size, "%H:%M:%S", gmt); // same idea as line above, but cleaner
return buf;
}
void main(void) {
char date_buf[9];
printf("%s\n", time_stamp(date_buf, sizeof(date_buf)));
}
Higher level programming languages hide all this complexity away, returning a string from a function is a no brainer. Thinking about it for a second, I’m assuming they store strings on the heap, then use garbage collection to free up the memory once it’s no longer in use.
I’ve skipped over some detail here, just casually talking about the stack and the heap like everyone knows what they are. I’m not sure I'm getting the level of detail for these posts correct, I should probably tell people about the blog and get some feedback. That said, I have to remind myself this is a journal and not a tutorial. I can always return to these topics later if I decide to explore them in more detail. In the meantime if you have no idea what the stack or heap is but want to know more, I recommend a google search.
Lists
Next up I wanted to play with arrays that could grow. This code is just an evolution of what I’d already copied from Beej’s guide for maintaining an array of sockets for polling. The big change is I wrapped up the three variables I need to track the array (the current size, the current count and a pointer to the array) in a structure. This way I could pass a single thing to the various helper functions when adding and removing entries. This is essentially a poor man's object orientation.
I then played around with structures a bit more and made myself a linked list of strings. To stretch my pointer logic muscles, I used a pointer to a pointer to keep track of the trailing next pointer. This would speed up add operations because I don’t have to search the list for the end. It may have been conceptually easier to track the tail node but then the code would have been more complex as I have to deal with more edge cases like when the list is empty. Tracking the pointer and not node means I can treat the head pointer and the next pointer in any node the same. And it helped boost my confidence with multilevel pointers.
I also reminded myself how to define a function that takes a pointer to a function as an argument so it can be called later. The syntax can get a bit ugly defining the function pointer type, but this can be mitigated using a typedef to give it a nice name. Also because C is weird, you don’t have to dereference a function pointer to use it. In-fact the dereference operator just returns the same pointer to the function. So does the address-of operator. This is somewhat different from how it works with normal variables but makes the syntax for using a function pointer very clean.
#include <stdio.h>
int add(int a, int b) {
return a + b;
}
int mul(int a, int b) {
return a * b;
}
int do_sum(int (*callback)(int, int), int a, int b) {
return callback(a, b);
}
typedef int (*op_t)(int, int);
int also_do_sum(op_t callback, int a, int b) {
return callback(a, b);
}
int main(void) {
printf("direct\n");
printf("2+3=%d\n", add(2,3));
printf("2*3=%d\n", mul(2,3));
printf("callback\n");
printf("2+3=%d\n", do_sum(add,2,3));
printf("2*3=%d\n", do_sum(mul,2,3));
printf("typedef callback\n");
printf("2+3=%d\n", also_do_sum(add,2,3));
printf("2*3=%d\n", also_do_sum(mul,2,3));
return 0;
}
Clean Tinn
Feeling much more comfortable with C, it was time to implement my lessons learnt and start the big refactor of all my code up to this point.
Static files
I started with how I was storing the list of available files the server could serve. I created a linked list of strings. In fact two strings, one being the local path, the other being the server path. Maybe overkill but it replaces the statically sized 2D array I was using before. That was a ticking time bomb waiting to crash my program. I also have vague intentions to expand the list to store other useful information at a later date, like the date the file was last modified, maybe even an in-memory cache of the file.
I also changed the program so it doesn't just serve the current directory (and its descendants). Now you have to pass a command line argument to the program to specify the directory. Much more convenient.
Sockets list
I created a structure to manage the array of open sockets. This started very similar to the string list example above, which as I said was based on the code I already had to manage the array of open sockets.
However, for every socket I needed more than just the poll file descriptor. I wanted to move the code that processes the socket whenever it has data to a separate function. I also wanted a flexible way to store state information about each socket. To achieve this I created two additional arrays, one of function pointers and one of magical void pointers (pointers that can point to anything).
All three arrays should always contain the same number of elements, I can therefore re-use the size and count variables used to manage them. I can also use the same add and remove functions to update the arrays and keep them aligned.
I could now move the code for handling sockets out of the main loop and out of the main function. I created two functions: server_listener and client_listener to handle each type of socket and passed these to the socket list. This made the code in the main network loop very short and tidy.
// loop forever directing network traffic
for (;;) {
if (poll(sockets->pollfds, sockets->count, -1) < 0 ) {
perror("poll");
return EXIT_FAILURE;
}
for (int i = 0; i < sockets->count; i++) {
if (sockets->pollfds[i].revents & POLLIN) {
sockets->listeners[i](sockets, i);
}
}
}
Server listener
The server_listener’s main job is to accept client connections and add the new client socket to the list of sockets. In addition to the socket, this code also creates a pointer to a client_state structure which I use to store state information about each client including the client’s IP address and an input buffer for requests.
Client listener
Up to this point I was quite pleased with my refactor efforts. I’d broken the code down into nicely sized functions with everything looking quite neat. Then I wrote the client_listener function and it’s a mess. Part of the problem is this is where the actual logic of a web server needs to go and part of it is I’m not ready to write a full on interpreter yet to properly parse the incoming request. That job is moving swiftly up my priority list but for now I just hacked it together.
The code reads as much data as it can. It then loops over each character looking for the location of the first space character, and the second space character, and a blank line. If it can’t find a blank line, the request header is not complete and so the code doubles the size of the input buffer and will try to read the rest of the request on the next go around the main poll loop.
If it found a blank line, the request (header) has been received, so it can be processed. This is where the location of the first two spaces are important. They define the first two words in the request aka the method and the path. It’s then a matter of routing the request and returning the correct content if it’s a valid request or an error code if not.
Compared to the original code I think the important difference is each socket has its own buffer for the incoming request (stored in the client_state structure) and I read all the way to the blank line before processing the request and attempting to send a response. Considering that if the buffer fills up it can take a few times round the main poll loop to read the entire request, it seems silly I tried to do this before with a single input buffer. To be fair to me, I was trying to just read the first two words and discard the rest of the request. It would seem that it doesn’t work that way. I could be wrong and this made no difference, but (spoiler warning) my new version does seem to be fixed.
Reflecting on what I was seeing in the network tab in the Chrome developer tools, the original version would stall at the initialising connection phase, not in downloading the response. It would seem then that the problem did lie with how the server was reading the request and not how it was formatting and sending the response. Since then I did (accidentally) create a malformed response with truncated content and the status of the request in the Chrome developer tools tab was clear the stall was in the download phase. The tools were pointing me in the right direction, I just didn’t know how to interpret them correctly. A lesson learn’t.
Buffers
The last big change I made was creating a series of functions to handle expandable buffers. I probably over engineered this but it helped me further my understanding of building character arrays incrementally. I’ve used them for receiving the request from the clients and for composing the responses.
As I reflect on this code, there is a quiet voice in the back of my mind telling me I need to read up on streams in C. Something to add to the reading list.
Does it work?
Yes it does. I’m not getting stalled sessions anymore and the server seems much more responsive in general.
I’m fairly certain giving each client socket its own input buffer and making sure I read the entire request before responding is what fixed my problems. Equally it could be my improved understanding of arrays and strings in general and I’ve corrected a weird memory bug. Whatever the reason, I’m much happier with the code now and I’m beginning to feel more comfortable that I know what I’m doing.
Testing, more testing, always more testing. I’m going to add some CSS files to the mix and see what that breaks. But the next big priority is to get the server to properly parse and act upon the incoming request headers. Which means I really should read that book I have on interpreters.
It was all working fine when I tested it on my local machine. Then moved it to my server and tested it from an external IP, I kept getting timeouts and disconnects. It was late so I left it and returned to it today.
I’ve not yet worked out the solution but I think I understand the problem. Basically I was closing the socket too fast, so the connection gets killed before all the data has downloaded. When testing locally this was not a problem, put a router or two and an ISP between me and the server and it is. The solution would be to not close the socket, in fact HTTP 1.1 is supposed to use persistent connections by default. This is how I had my code at an earlier point on the project, only closing the client socket when the client sent zero data AKA a disconnect request.
However, I then see a problem in Chrome where the first request loads fine but the second request never finishes. According to my server console the second request is received from the client and the response is sent. According to the network tab in Chrome developer tools the connection is stalled at the initialising connection phase. Closing the socket from the server side seems to complete the request from Chrome’s point of view. This was why I changed my code originally and made a mental note to look deeper into persistent connections.
Now I’m sending more data, like images and more text, it seems I have to give the socket time before closing it otherwise the data gets truncated. But leaving it open caused Chrome to freak out. I’m obviously doing something wrong with how I’m handling the connection and sending the data. I think I need to do some proper reading of the HTTP spec. It was only a matter of time.
That said I did some hackery to make the site work while I go read. I now don’t close the socket after sending a response, which avoids the router problem. I then have a 2.5 second timeout which will close all client sockets if no other activity has happened, which works around the Chrome problem. It’s not neat. It’s not going to work if any number of people use the web site at the same time. I’m not proud of it. But it works for now.
I’m feeling the need to better track connected clients, especially if I’m going to maintain persistent connections. Generally I need to tidy up the code and move some of the network setup out of the main function. The next version is going to have quite a few changes I think. This is why I’ve tagged the current hacky state as v0.2.0 on github.
Interestingly, Firefox does not have the same issue as Chrome when I keep the socket open. I assume it’s being more forgiving and that I’m not that far away from the correct handling. Also, because I can see the sockets being opened on my server in real time, I now know that Firefox will open the socket as soon as you hover over a link in your browser. I assume they do this to get the TCP handshaking out of the way before you click the link to make the browser more responsive. Similarly Chrome always opens two sockets, again I assume for performance reasons, but in my tiny example I’ve never seen it use the second socket.
I’m off to read, be back in a couple of days I hope.
Doh. The problem with the UTF-8 was nothing wrong with the C code, but I forgot to set the charset in the HTTP response headers, I should have got that sooner. It makes sense as I’m not manipulating the content, just reading it from a file and sending it to a socket. The only function I’m really using on the temporary string is strlen which in this case will return the number of bytes, which is what I need, and not specifically the number of characters (beacuse some of them are multiple bytes long), which I don’t particularly care about. As it happens I didn’t even need to use strlen, I’ll come back to why in a moment.
I’m actually setting the character set in two places now. First, in the HTTP headers I have set Content-Type: text/html; charset=utf-8. Second, I’ve added the HTML header <meta charset="utf-8">. The second one is more out of habit than anything. I was not sure if it is strictly necessary, a review of the spec suggests not, but every boilerplate HTML example I found includes it, so I’ve left it there.
I’ve updated the server to be able to serve more than a single page. I was worried about accidentally granting everyone access to all the files on my test box, so I’ve taken what I believe to be quite a defensive approach. When the program starts, it scans the current directory and recursively builds a list of files available. Then when the server receives a request for a file it will only respond if that file is its list. This does means that if I add a file I have to restart the server, which is fine by me until I build up my confidence in validating client requests. Also I’m not a total noob, I’m running the server with an ID that has very limited access.
I created a new function that based on the extension of the file works out the mime type for the HTTP header, I assumed there was a far smarter way to do this but a cursory glance suggests not. I’ve intentionally left room for future improvement by using a big laddered if statement. One day I will replace this with a proper list of file extensions to mime types and a lookup or something.
As for sending images over HTTP, the only real change I needed to make was to stop treating the data I was reading from the files as a null terminated string and instead as an array of bytes. Most of my code was already set up for this, so it took about 30 seconds to fix it once I realised my error in thinking. This is another example of my lack of experience coding with C. I saw errors the other day using strlen to work out the content length and fixed it by null terminating the string when I should have realised I already knew the length from when I read the file. Fixed now. Clearly more practice is needed.
I would like to introduce version 0.1.0 of Tinn, my web server. You can see the full source code on github. Most of the credit has to go to Brian "Beej Jorgensen" Hall and his book "Beej's Guide to Network Programming using Internet Sockets". You can check out the book on his web site at https://beej.us/guide/bgnet or like me you can can buy a real world physical copy.
A check of the source code for my server will show that a good chunk of the code comes straight from Beej's book. To be fair to me, I typed every character myself, this is part of my learning process. If I just copy and paste code, it doesn't go in my head, but if I retype it, I'm forced to think about it which I feel helps me learn.
This is not going to be a tutorial, so I'm not going to explain every line of code. First others have already done a better job and second I'm not that confident my code doesn't have a horrible memory leak. That said, here is a quick breakdown of how the code works. It's all in a single file stub.c for now because the whole program is only 225 lines long. Skipping to the main function on line 92, I start with all the networking stuff which in summary completes the following tasks:
Gets address info for the local machine
Creates a socket
Binds that socket to a port
Starts listening to that socket
Adds that socket to a list of sockets for the call to poll later
The server then enters an infinite loop which polls its list of sockets for when they have something to say. Initially the list will only contain that first server socket. When it does have something to say, it's because a client wants to connect to the server. In this case the program accepts that connection creating a new socket for that client. This new client socket is then added to the list of sockets to poll.
When a client socket get's chatty, it's because the client is making a request. This is where the code leaves the comfort of Beej's guide and instead we have to start thinking about HTTP. For now I'm ignoring most of the request and just concerning myself with the first two words. In an HTTP request the first word is the method, the second is the resource path. I will worry about the rest of the request at a later date.
At the moment the server only supports the "GET" method, and only supports the path "/". For any other method the server responds with an HTTP error code 501 (Not Implemented) and for any other path responds with a 404 (Not Found). For a valid GET / request, the program loads the contents of the content.html file, composes the correct HTTP response with the appropriate headers, Content-Type and Content-Length being key and sends the response. The client socket is then closed and removed from the list of sockets.
That's it. Step one complete. I have the beginnings of a web server. I have a much better understanding of how sockets work. Most importantly, a list of things I'm eager to do next.
First up, this has highlighted how rusty my C coding is. Specifically I need to review how strings work. I'm fairly certain the way I'm composing the responses is suboptimal. I didn't expect this to trip me up, but years of working in higher level languages has left me reaching for a concatenation operator that does not exist.
On a similar note, the server has an issue with unicode. The UTF-8 content file had some characters (e.g. fancy quotes) that used more than one byte to encode the character, these got corrupted somewhere in the chain, I need to fix that.
Then I need more functionality, starting with being able to return different files based on the path and for those files to support different content types. Then I plan to add some much needed style to this blog. How do images work over HTTP?
It's really simple and probably has some issues but it does seem to be working. For now all it can do is serve the one page at the root and otherwise returns some error codes. I'll go into details later, but as the blog is now live I thought I should at least acknowledge that. Nothing like testing in live.
Part of the reason I've procrastinated about this project for so long is its insanely ambitious. Domino is a commercial product and I work in a commercial environment so it's all too easy for me to think in commercial terms. This sets the bar for success way too high. Instead I really need to reframe the project and set some realistic goals. This is an opportunity for me to learn and expand my skill set and do some regular coding. This should be a literal hobby project.
The goal is therefore to build an experimental platform for developing, hosting and administering web applications that I'm happy to use for my personal projects. I am the only customer. This is a toy for me to play with and while I'm willing to share my toys, it's my toy and I'm picking the colour. Success will be measured by how much I learn, how much coding I get to do and how many puzzles I get to solve.
It's still an ambitious project so it does require some level of planning. I don't have a complete roadmap yet, but I know how I'm going to start.
First I need to implement a basic web server. This doesn't mean installing one of the many existing web servers, or even using a library to add one to my program. That is not how Lotus did it back in the 90's (I assume) and this is supposed to be an opportunity to learn. This means grabbing my book on socket programming and writing my own web server from scratch. Its first job will be to host this blog. I doubt it will be a complete web server, or even a good one, but I should have learnt something and it will be a base on which to build.
The next three deliverables, and I've not yet decided on an order are: a simple flat file database; an interpreter; and encryption.
The long term goal is to create a document oriented database. This is a massive project in itself so initially I'll create a simpler flat file DB. I've done this once before (20 plus years ago) and so that seems like a good place to start. I'm hoping I'll be able to build on that and iterate into a fully fledged DB over time.
If this is to be a development platform, at some point I'm going to need to read and execute code. This is where the interpreter comes in. More than that though, I think the interpreter will be useful in lots of places. A web server for example needs to parse and act upon requests. This sounds remarkably similar to what an interpreter does. This makes building the interpreter a strong candidate for my second priority.
Encryption should be a core component of the platform. It will be needed in the web server to support HTTPS. I want to be able to encrypt the on disk database. It will also be needed if I implement any kind of code or document signing. This may be an area where I let myself use an established library, it's a lot of complex maths I don't want to get wrong. However I want to understand how it works, so before using someone else's code I plan to get some books on the topic and create my own implementation of some common encryption algorithms.
Later I'll need to build web interfaces for server and database administration. I'm also going to have to build an IDE at some point. I'll realise what a huge and silly idea this is if I think about it too much more. For now I'll just hide those on a list somewhere and move on.
That is about as much project management as I can tolerate for a hobby project. Time to start coding. With any luck my next post should be about how I implemented a basic web server.
I'm a Domino Developer. While that has not been my official job title for some years, I continue to use Domino to develop web applications to this day. It's certainly not a popular option and when it comes up in conversation people are mostly confused. Some had assumed Domino was a retired product no longer in use while others have never even heard of it. I get the impression some of my non-technical friends are still trying to work out what pizza has to do with computers.
In May 2021 to coincide with the release of version 12 of HCL Domino, I started writing an introduction to Domino for those who had never considered it as an application development platform. I was going to explain how I used Domino, what parts I liked and which bits to avoid. But as usual I got distracted, never finished and the moment passed.
With my plan to explore what it would take to build a replacement for Domino, it seems a good place to start would be to complete that post explaining what I like about Domino and make it clear what I'm trying to recreate and what I'm trying to avoid.
What is Domino?
Let's start by clarifying what Domino is. Back in 1989 the Lotus Development Corporation released Lotus Notes. In 1995 IBM purchased Lotus but the branding and the name remained unchanged. In 1996 a server add-on called Domino was released for Lotus Notes 4 which allowed the rendering of Notes applications as web pages. When version 4.5 was released, the web engine was integrated into the server and from this point on the client was referred to as Lotus Notes and the server as Lotus Domino. In 2012 IBM dropped the Lotus branding so it became IBM Notes and IBM Domino. Then in 2019 IBM sold the product to HCL and we arrive at the current names, HCL Notes and HCL Domino.
Personally I tend to drop the company name and mainly use "Domino" in conversation. I use this as it has less stigma and is technically correct for the way I use the product. When I do use the term "Notes", it's because I'm talking about something specific to the client.
My experience
I started using Domino in 2001 when I worked for IBM. I was part of the support team for the internal Domino environment hosting mail and applications for all the IBMers.
This team had no involvement in the development of Domino. We occasionally got a preview of the new version, but mainly we were treated as an internal customer. I stress this to make it clear I had no influence on the direction of the product. In fact since leaving IBM and becoming a paying customer, I've had a louder voice.
I carved out a niche for myself writing tooling and automation to assist with various tasks and projects. However I wanted to do application development full time, so in 2007 I accepted a position in another company as a Domino Developer.
My new role was to develop, maintain and support Domino applications that were used in the day to day running of the business. When I started, most of the applications used the Notes client, however the effort to move these to web based applications had already started and that was part of the reason I was recruited.
I spent the next six years writing web applications in Domino. I'm proud of the work I did and the applications I developed, I've had some very complimentary feedback over the years. It seems the company was also happy and in a misguided attempt to clone me, they promoted me to team leader so I could develop people in addition to applications. Results have been mixed, but development has continued and still in Domino.
Domino's replacement
In 2014 the company I worked for was purchased and integrated into a larger organisation. As you can imagine, this integration caused lots of changes to the IT landscape.
It wasn't long before we migrated email to Exchange/Outlook. The simple document repositories and Quickr sites slowly moved over to SharePoint. Sametime hung on for a while longer but it was eventually replaced by Skype For Business which was quickly replaced with Teams.
The custom applications though were a different story, there was no obvious easy replacement. Not long into the integration it was my job to present an overview of how we were using Domino and what applications we had developed. I got the impression our new colleagues initially dismissed Domino as a poor email system, but were then taken aback at how widespread its use was and how critical it was to our business.
It's not an exaggeration to say Domino was supporting most parts of the business. An abridged list of what we where using Domino for at this time includes:
Organisation chart
Vacation planning
Annual appraisals
Recruitment
Travel planning
IT service management
Customer relationship management
Quote generation and order entry
Kanban scheduling
Shortage tracking
Non stock order tracking
Service management
Engineering change control
Project management
Defect management
Software lifecycle management
Internal audit tracking
Our website
Our intranet
The supplier and customer portals
Including the simple document repositories and typical workflow/approval apps, we had well over 100 Domino applications in active use.
There was however still a resistance to continued use of Domino, partly because at the time IBM seemed to be neglecting the product, and partly because it was unknown to a large part of the wider organisation. My task now was to review alternatives to Domino and detail what a migration plan would look like, or justify why we should continue application development in Domino.
We reviewed open source options, we looked at Microsoft's offerings, we looked at SAP, we looked at other products from IBM, we reviewed half a dozen application builders. We spent two years on and off reviewing alternatives but none of them seemed suitable replacements.
I was honestly eager to escape Domino and all its quirks and frustrations. After years of being told how terrible Domino was I was expecting to find a variety of superior replacements. I was surprised to find out Domino is peerless and replacing it would require a combination of products and bring a whole new set of challenges and frustrations.
Domino, it turns out, is a good application development platform. Like everything it has pros and cons, but its advantages are in areas businesses care about and its disadvantages can be managed. It helped that IBM eventually partnered with HCL and we got a new version but ultimately I feel we stuck with Domino for three reasons: security, being a complete package and cost.
But the UI is so bad
Some of you who have used Notes/Domino before are probably now thinking I've lost perspective, after 24 years I've become brainwashed. I'm guessing you have some real horror stories about how bad Notes is and would be more than happy to tell me how I'm wrong.
The thing is I agree, the Notes client is a mess. It's a user experience nightmare and I actively discourage its use. Fields don't look like fields. It has three different types of tool bar. It has three types of search that don't seem to work properly. There is a fiddly little property box which is essential for some things and hidden when you need it. The keyboard shortcuts are weird. And it's slow and always hanging.
Being an apologist for a few moments, version 1 was released for DOS and OS/2 in 1989. The intention was for Notes to be consistent across all platforms and the standards for GUIs were thin on the ground in 1989, I therefore assume Lotus took the best ideas at the time and came up with their own standards. Then as subsequent versions have been released a key goal has been to maintain backwards compatibility. As almost all the content in Domino is custom applications, the GUI components could not be modernised without giving all the existing customers a ton of work to do, testing and potentially re-developing their apps. So those components stay looking as they did 35 years ago.
The Notes client was probably amazing by 1989 standards. While the prioritisation of backwards compatibility explains some of the odd visuals it does not excuse the lack of progress in other areas. Like why is the property box still so tiny? Why can't I reorder tabs on my workspace? Why can't I map a keyboard shortcut to deselect all documents?
Who needs the client
The good news is you don't need the client any more. As I mentioned before, starting with version 4.5 in 1996, the server now supported HTTP and would serve applications as web pages. The truly impressive thing is this worked with no additional development. Build your app in the designer client as normal and all the forms, views, actions and navigation would be automatically converted to web content by the server on the fly. Low-code web development in 1996!
The problem is the pages looked, and still do, like web pages from 1996 and any user interaction requires a full page load. JavaScript is used but very sparingly and there is no CSS. The technology was impressive at the time, today it looks and functions terribly.
Not to worry, Domino provides various ways to inject your own custom HTML into the pages to make them look and work as modern web apps do. You can do this for small parts of the page and let Domino generate the rest automatically, or you can disable the automatic generation completely and develop the web front end as you would with any other technology. With JavaScript and CSS library support, you have complete control over your user interface and all the goodness of the Domiono back end, which I'll get to in a moment.
This is how my company developed its web applications. We built a library that initially mimicked the functionality of the Notes client but with a modern look. We then expanded that library with a framework for single page applications.
IBM were having similar thoughts because with version 8.5 they introduced XPages. This provided a way to build modern looking single page web applications with Domino as a back end. It was based on JavaServer Faces and used Dojo for the front end. I believe the intent was this would replace traditional Notes client and "classic" Domino web development, however it would require the re-development of applications, so adoption was very slow and the older technology would need to be maintained for backwards compatibility.
HCL has also introduced a variety of ways of accessing Domino without using the Notes Client. In version 10 they introduced a new Domino Query Language (DQL) and added support for node.js to query Domino applications. They have also been slowly expanding on the REST API. The implication being that you can use any front end that talks HTTP.
One of the biggest complaints about Domino, its user interface, can be neatly side stepped by using the web instead. The question remains, why use its backend.
The database
At the core of Domino is a database. The NSF (Notes Storage Facility) is a NoSQL, document oriented, distributed database. It was ahead of its time and offers security features I've not seen available in any of its contemporary rivals.
I find document oriented databases particularly good for supporting workflow applications, replacing paper based forms and in general modelling the kind of data business need to store. It is useful to have the flexibility of a document oriented database in the real world where business requirements are always changing. As a result I find it much quicker for the kind of development I need to do. The rise in popularity of NoSQL databases like MongoDB show I'm not alone in this view.
The strongest feature of Domino's database is its security. This starts with the Access Control List or ACL. The ACL offers seven broad levels of access with options to refine this for specific actions like creating and deleting documents. It supports explicit names, hierarchical names and groups. It can distinguish between servers and users. You can set the access level for unauthenticated users differently from authenticated but otherwise unlisted users. You can map names and groups to roles. It can do a lot.
There is an often overlooked dual level to the ACL, you can classify data and design elements in the application as public, then control access to these separately. This is particularly useful for public facing applications where you might want to give an anonymous user access to the landing page of an application and a few key documents but not the majority of the app.
Where Domino security really distinguishes itself is the document level security provided by the readers and authors fields. Add a readers field to a document and only those users (or groups or roles) listed in that field will have access to that document. You can add as many readers fields as you like and they can be computed or user editable. With this system it's really easy to create a security model for even the most complex scenarios.
A practical example of where this shines is a yearly appraisal system. Each appraisal needs to be seen by the employee, the manager, the local HR team and the global HR director. No two documents in the database are going to have the same list of people who need to access it. In Domino this can be achieved by making the employee and manager fields reader fields. Then adding a computed readers field which works out the group name of the local HR team based on the employee's location. Finally add a computed readers field with a static value of the HR Director role.
Obviously there are ways to do this on other platforms. Relational databases offer row level security but it tends to be role based which would not work in this example. A common approach is to then add the security logic to the application and generate a query to only return the appropriate records. The problem here is if someone were to get direct access to the database, accidentally or maliciously, they could see all the records.
MongoDB has a redact aggregation feature that can achieve something close to what we require. However, as I understand it, this is similar to a query in a relational database and there is nothing stopping the developer from accessing the document collection via another method without that security logic.
My point is that in every other platform I've seen, this type of security is achieved by adding a layer between the database and the user. Every layer is potentially a point of failure and it is not always the case that the only way to access the data is via that security layer. In contrast, Domino has this security baked in at the record level. Readers fields are easily added to a document and once added are always honoured. This makes it very hard for a developer to make a mistake and leave open a path to these documents.
It's not infallible and we still need to audit our work. Compared to other solutions however, once audited you can have a higher level of confidence the data is secure as there are less places it can go wrong. In a business context this is a highly desirable feature and in my opinion one of Domino's killer features. It's one of the reasons we are still using Domino today.
The development tools
Domino applications are developed using an IDE (integrated development environment) called Domino Developer. This sits in a space that crosses both low-code and pro-code development.
Historically, Domino applications were simple and developed using a tool set aimed at business users, what today we would call citizen developers. For example, forms are built in an editor very similar to a rich text document editor. If you're comfortable with Microsoft Word, you're most of the way there. It's not the drag and drop style editor lauded by modern low code platforms, but it is similarly intuitive. You also don't need to design the database separately, when you add fields to a form, Domino will do the rest for you.
Domino moves from no-code to low-code with its Formula Language. Computed fields, view columns, view selections, actions etc. all use this Formula Language. It is sometimes called "at-formula" because all of its functions start with the @ symbol. It is similar in complexity to the formulas you would find in a spreadsheet and so still aimed for use by citizen developers.
Later versions of Domino introduced LotusScript. This is a general programming language with syntax similar to Visual Basic. It supports procedures, functions and object-orientation and comes with a complete class library for manipulating Domino applications. It is far better suited to more complex tasks or where reuse is required. It is also where we start to lose citizen developers and need professionals.
The all purpose hero of automation in Domino applications are agents. These are self contained units of code that can be triggered from actions, events, the web or on a schedule. It is agents that turn document repositories into workflow applications and beyond. Predictably they can be written using Formula Language or LotusScript. They can also be written using Java, and you can import any custom or 3rd party libraries you need. This really raises the bar for what you can code in a Domino application.
As mentioned previously you can (and should) override the default HTML generated by Domino when an application is accessed via a web browser. This adds HTML, CSS, and JavaScript to the mix of technologies in use. The skill set required to develop a modern Domino web application is not too dissimilar to other full stack developers. Web technologies for the front-end, LotusScript and/or Java for the back end, Domino for the database.
It can be argued that Domino is the original low-code development platform, I've heard some people actually argue that. While true for some simple types of application, it's not really true for most. When I started Domino development it was described as Rapid Application Development or RAD. I prefer this term because it more closely describes the situation. Domino makes some common development tasks as easy as point and click, which in turn makes development surprisingly quick. However, it also comes with the tools to go full pro code when required.
Domino Designer is installed alongside the normal Notes client, it shares all the same authentication and connection profiles, as a result it requires almost no additional setup. You don't need to worry about installing plugins or connecting to project repositories, it just all works out of the box.
It's not all roses however, the IDE is ageing and in desperate need of some upgrades. It is largely based on Eclipse with some editors that have been lifted from the older pre-Eclipse version. It has some interesting bugs especially with how some of the side panels are rendered. Most annoyingly for me however is the JavaScript editor does not support ES6 and refuses to save valid JavaScript because it fails its outdated validation.
When introducing new developers to Domino, particularly graduates, the state of Domino Designer is a cause of much embarrassment. When compared to modern text editors and IDEs it does not fare well. The lack of a dark mode is almost a show stopper for some grads. It takes months before they can see past the quirks and issues and recognise Domino's value.
Domino's RAD development approach is a genuine advantage and an important part of the product. However RAD development is not unique to Domino and the outdated IDE lets it down. Therefore in my view, it is not one of the killer features, but certainly an honourable mention.
Self-contained
A feature I particularly appreciate is how Domino applications are self-contained in a single NSF file. Documents in a Domino database can store anything, normally this is a collection of fields, however it could also be binary data. The application can therefore store its own design including all the forms, code, images, libraries etc. There is never a question of where the logic for an application is, it's in the same database as the data.
This is the reason why the terms "database" and "application" are often used interchangeably with regards to Domino. They have the same scope and are mostly the same thing.
It has several advantages from an administration point of view. For example, to backup an application you need to copy one NSF file. This will give you all the data, logic and meta-data required for that application to run. If you need to move an application to a different environment, just copy over that single file. Normally the only extra thing you need to consider are users and groups, which by default are also stored in a Domino database, just a centralised one used by all the applications.
This also makes application deployments a breeze. Any NSF can be marked as a template and Domino provides a system to synchronise design elements between templates and other databases. Upgrading an application is a simple process of creating a template and triggering a design refresh. Rolling back requires restoring the previous template and triggering a design refresh. All the effort really goes into template management which just requires a little bit of discipline.
When deploying an application, there are no extra steps to link the application to the database, by design they are already linked. In fact the database, the web server, server side engine, scheduled tasks, email, user authentication, everything you need to run an application is all provided by Domino. Obviously some of these require configuration when the environment is first set up, but come application deployment time it is extremely rare if you have to do anything other than the design refresh.
Deployments only become a chore if you also have to manipulate the data as part of the upgrade. With Domino being a document oriented database, my experience suggests this is the exception and not the norm.
As a result the operational part of Domino has a very low cost and depending on the company set up, it's quite practical for developers to be responsible for operations. When DevOps started to become a thing, I was pleased to discover I'd been using the new paradigm for years, I just didn't know it had a name.
Consider a similar application with Microsoft technology. You'll need SQL Server for the database, IIS for the web server, AD for user and group management, Exchange for email, DevOps Server for package management and deployment (I think) and Visual Studio for the actual development. Each of these are their own discipline, with their own installation processes, individual set up, separate tools and training courses. Developers need to understand the different APIs and how these applications wire together. Administrators need to maintain multiple products, or in my experience I'll need multiple admins each specialising in a different product. Operations are more time consuming, requiring updates to multiple products and maintaining the links between them.
Domino in comparison is installed as a single product and administered as a single unit. With some rare exceptions all the configuration is stored in Domino databases that can be edited using either the normal Notes client or an advanced client called Domino Administrator. It can get complicated for larger environments, but in comparison it is relatively low effort. For example when you configure the security in Domino you have secured the database, the web server, email, everything in one go. With other platforms you may have to repeat that process for each product.
Domino's all-in-one approach also makes it more reliable. For example you don't need to worry about dependency management. There is never going to be a time where the database gets upgraded to a version the web server does not support. You're not going to need to spend time diagnosing why product A has suddenly stopped talking to product B even though no one claims to have changed anything.
Ultimately Domino being a single platform saves time and effort, it improves security and increases reliability. Developers can spend more time on development and less time context switching between technologies. Administration requires a minimal amount of resource, and there is no need to spend time linking databases to web servers and server side backends. What company doesn't want to have its staff focused on the value add and avoid non-productive time? For me, Domino being a complete package is killer feature number two.
The alternatives
There are other solutions which claim to be modern replacements for Domino.
Microsoft SharePoint is often cited as a replacement and while it is fine for simple document repositories it is not an application development platform. For SharePoint on-premise you used to be able to use tools like InfoPath or SharePoint designer to customise it, however both of these have been discontinued. There are third party tools like Nintex you can also use to customise it. However it might be easier to abandon SharePoint and develop a traditional .NET app instead.
For SharePoint Online you very quickly end up realising what you should be using is PowerApps. And maybe Microsoft Dataverse. This then starts to look suspiciously like Microsoft Dynamics 365, and you start to wonder if you should use that instead. It may all have Microsoft branding and be available via Microsoft 365, but you are back to the problem of needing to use multiple products. It's also not entirely clear which products to use when and if you are even licensed to use them.
For application development, a better fit seems to be the various no/low code platforms. Nintex seems to be slowly detaching from SharePoint and marketing themselves as a stand alone no/low code platform. K2 was in this market until Nintex purchased them. Outsystems and Mendix are also marketed as no/low code application development platforms. HCL even has Volt MX.
I feel that no/low code is a misleading marketing term as it's not strictly true. For tools that are genuinely no or low code and intended for use by citizen developers, you very quickly hit a ceiling of what can be done with the tool. You end up trying creative, often time consuming, workarounds to build the logic required. At this point the tool is more hindrance than a help and the logic could have been described far more clearly and quickly with a few lines of code. It seems that any sufficiently mature no/low code tool has already arrived at a similar conclusion and provides a way to enter code when the point and click interface reaches its limit.
This is not unlike what I previously described with Domino Designer, where initially the tool may have been intended for business users but over time has expanded to support professional developers. Nintex, K2, Medix, Outsystems and Volt MX all fall somewhere on this spectrum and therefore, at least from a development point of view, are potential replacements for Domino.
Another way to view these platforms is "low admin". What they do well is take all the various components you need to run an application, package them up and provide them as a single installed program or online via SaaS (software as a service). All the various configuration, dependency and security problems I was discussing in the previous section are absorbed by the platform. What administration is left is all done though a nice portal and development is completed via an IDE.
The big problem is these systems can get expensive, especially the SaaS ones. I can't give exact numbers, quotes depend on many factors, but they are at least an order of magnitude more expensive than what we are paying for Domino. In Microsoft's case this is in addition to the licence we already have for Office, SharePoint, Teams etc. For most of the other products, we would also need to licence a database to be used by the system as that is not included.
It would seem the reason Domino is cheaper for us is the way it is licensed. We buy a utility server licence, this is basically a per server licence that considers the speed and number of processors the server has. The other solutions are based on either the number of users and/or the number of applications. If you have a lot of apps and/or a lot of users, this very quickly adds up.
HCL also offers per user licensing for Domino. They have for many years now been encouraging customers to switch models. Every time I renew our licence, our HCL Business partner say we should switch and after reviewing our user numbers come back with a per server quote anyway. My own estimates with publicly available data put the costs inline with the other platforms, somewhere between ten and hundred times more expensive. If we were using all of Domino's features and our users were using the Notes client we would have to switch to the per user licence. Having developed all our applications to be accessed via a web browser and only using the application development and hosting features means we can just licence the server.
It's very hard for a business to justify the increase in expense when comparing Domino to one of the other solutions. Ultimately sticking with Domino is the wise choice. This in my opinion makes Domino's per server licensing model killer feature number three.
What HCL are up to?
HCL announced they are discontinuing per server licensing.
The announcement describes this as "License Simplification" and how per server licensing is "based on Processor Value Unit licensing, an old license metric no longer relevant in a modern Cloud / Kubernetes world". You can read the full blog post here.
I'm sure for some customers this is a non event. I guess it depends on how you use Domino. We've been told that the switch should be cost neutral, but I've never had that in writing and I'm still waiting on a quote using the new model. I know what the normal per user cost is and what we are currently paying and the maths doesn't work. It's going to be a tough pill to swallow when our licence is up for renewal, and I'm going to have to once again justify Domino to management.
HCL purchased Domino in 2019 and since then have continued to invest in the platform. There has been about one release per year. Beyond the bug fixing and what I imagine is a massive technical debt that needs addressing, HCL have released a few big ticket items.
For example, HCL released the Nomad client for Apple, Android and the web. This allows you to run Domino applications on mobile devices and in web browsers without any additional development. Applications look and work as they do in the normal Notes clients. This is a fantastic option for organisations who haven't already re-developed their application to work on the web, either using traditional Domino development or XPages. For us, it's of very little use as we already did the hard work.
HCL have also released Domino Leap (originally Domino Volt). This is a web based low code IDE that uses Domino as a back end. We've been trailing this for some time with business users who wanted to develop their own applications. In a familiar story the users quickly tried to do things the tool could not support and mostly gave up. Except for one user who found you can add your own JavaScript and has gone wild developing their own thing. To HCL's credit the release cadence for Leap has been about every 6 months and the product is much improved from when it first landed. Leap is however licensed as an add-on for Domino, so as useful as it might be, I can't use it to justify the increase in cost of the base product as I have to pay extra for it anyway.
There have been some improvements to the Notes client which generally I'm not interested in except they replaced the tiny properties dialog. Sort of. They actually added a second "advanced" properties box which can't replace the original as it only covers some of the original's functionality. So now I have two properties dialogs.
From a developers point of view I think the biggest updates have been a JSON parser in LotusScript and the new REST API. Domino 14 which was released in December 2023 included a new JavaScript editor, unfortunately when editing JavaScript libraries it still triggers an old validator on save that rejects ES6 syntax and refuses to save. They have also released a version of the Domino Designer that runs in the web browser in the same way the Nomad client works. This is marketed at those that wanted a Domino Designer client for Apple or Linux. I admit I've not tried this client yet but am curious to see if it fixes the JavaScript validation problems and rendering bugs with the properties panel still present in the version 14 Windows client.
As I struggle to recall what improvements we've received in the last four years which have made a noticeable impact to our usage of Domino, I realise this alone is not enough to justify a significant increase in cost.
Honourable mentions
I've not covered everything I like about Domino, this post has gone on long enough but before I conclude here are some honourable mentions.
The Domino database supports replication. This was more important to me than it is now. In the 00's when networks were slow, expensive and far from always on, we had a Domino server in each office and used replication to keep everything in sync. Today I have all my apps hosted on one server so I don't need replication, but it's there if my situation should change. Clustering is also supported, and as application usage grows I have started considering this as an option to add some load balancing and resiliency.
Domino is very backwards compatible. Applications that were written over 20 years ago for Domino 4.5 would still work today. In theory you can go back further, I've just never tired. In my experience the only problem we regularly get when upgrading Domino is the default fav icon is reset. Otherwise we take care to test anywhere we have broken out of Domino to access other systems or tools but the core Domino functionality keeps on working. This makes keeping up to date almost trivial and keeps our security team off my back.
Wait a second, what about email?
You may have noticed that I've not really discussed email. This is because I view Domino as an application development platform where one of the things it can do is email, and one of the out of the box applications is an email client. This is not how a vast majority of users see it, for them Notes is a bad email program that can also do other things. I understand their point, for a while Notes was marketed and sold as "just" an email solution, so many users only used it for email.
While the email functionality in Notes is comprehensive, it's different. Emails are (or were) referred to as memos, revealing Notes' age and a nod to the paper based internal memos Notes was replacing. This might have made more sense in 1989, but it's confusing for new users in the 21st century. Other terminology was similarly unintuitive, insteading of sending and receiving mail, you replicated your mail file. While technically correct and hinting at the much wider scope of the Notes program, for some uses it's simply confusing.
Add these usability issues to poor user experience with the client in general, it is easy to understand why anyone who had to use Notes just for email has been scared by the experience. For anyone still using Notes just for email and calendaring, despite the recent improvements, I argue you are using the wrong product.
Final thoughts
I'm not sure if the way in which we use Domino is rare or fairly common. Based on the features HCL seem to be focusing on, there are a lot of companies still using the Notes client and a lot using it for email and calendaring. This is backed up by the feedback I see in the Domino ideas portal. So on the surface of things we are a special case.
Anecdotally however there are also lots of companies who have migrated away from Domino for mail and instant messaging and simple document repositories, but are still using Domino for bespoke application development. This is sometimes because they could not find a suitable replacement or because they could never justify the resource required to migrate. It would therefore seem we are not unique in using Domino only for application development and hosting.
I'm curious to see if HCL reverses their licence decision, or announce a new additional model that works better for us. I guess that depends on how many companies push back on the change.
Meanwhile Domino's other strengths are still there. Security is second to none. Its self contained nature with design and data in the same database brings so many benefits to development, operations and administration. It is also one of the few options that does not require a separate licence for a database server. I therefore maintain it is a good platform for application development and none of the potential replacements quite measure up. Despite what happens to the cost, this may be the conclusion we reach at work, add in the effort to migrate and Domino is likely to stick around for a while yet.
I would however struggle to recommend Domino to a new customer. It has not aged well and there are way too many quality of life issues and quirks. This is especially true with Domino Designer. While these are largely minor problems that I've gotten used to or have workarounds for, they are barriers of entry for new users. For new members in my team, I can support them for the first few months as they get used to Domino, this is not the case for a third party and so I cannot confidently recommend it.
I hope HCL continues to make updates to Domino, address the bugs and quality of life issues and generally bring it up to modern standards. It would be nice if they could pick up the pace a little bit, the most popular requests in the ideas portal are now five years old.
I shall continue to watch and evaluate the alternatives. The focus on low code is a mistake in my opinion, it limits the scope and capability of the platform. Instead I'm looking for a professional development environment with tools to help speed up or automate the common standard tasks. I want a platform that lets me focus on development with administration and operational efforts as low as possible. Finally every time I realise I need to plug the platform into an independent SQL database server, my heart sinks.
I believe there is a gap in the market. Domino is good but in a desperate need of a tidy up and modernisation. The alternatives are getting better but are not complete. It is entirely possible I'm the only person who wants this exact combination of features which is why it does not exist. Then again, maybe I'm right, but that exact combination is really hard to put together.
Either way my next step is to have a go for myself. Let the learning commence.
I've been procrastinating about this for years. I've got excuses and a pile of false starts but this time it might be different, I hope. I've decided to write a blog.
I have things I want to say, things that might be interesting to others, but mostly things I need to get out of my head so they stop using up space. I've written a few blog posts before, my most successful attempts being a few articles I wrote for dev.to. I was happy with those articles and I may revisit those topics here. However, I want a place to call my own, where the posts can be a mix of journal entries and technical articles and cover non-technical topics. So a blog of my own it is.
Let me start by introducing myself, I'm TC and I'm a nerd. I work with computers and I play with computers. When I'm not computing I'll be building LEGO, or enjoying sci-fi, solving a Rubik's cube, playing D&D, dabbling with electronics, playing board games, drinking a Coca-cola, training at the gym, or thinking about that one time a year I get to go skiing.
Professionally I'm a senior manager and digital workspace architect. What that practically means is I do some consulting and designing. I do a lot of hand waving and attempt to manage a small group of analysts and developers to turn grand ideas into practical IT solutions. Sometimes though, I get to do some actual coding, and that is the bit I love.
I started my career as a systems administrator, all the time aspiring to be a developer, looking for any opportunity to code my way round problems. After several years I switched jobs and spent the next six glorious years as a bonafide application developer, great times. I then accepted a promotion and I've spent the last ten plus years with one foot in application development and one in all the other stuff I am supposed to do.
As I have moved up through the ranks, I get a decreasing amount of time to do the fun coding part. It annoys me that to progress my career I've had to take a managerial path and not a purely technical one. I have to keep reminding myself that I knew what I was accepting, it was my decision, it's a job after all and not a hobby. Yes I'm grumpy, but it really is my own fault.
For me coding is the ultimate puzzle. I enjoy the process, I enjoy the satisfaction of solving a problem. I like the way it opens up my mind, the sense of clarity it brings. I like that brief moment after solving a problem where I understand everything and anything is possible.
I've been chasing that feeling ever since the first time I experienced it decades ago in a maths lesson. We were exploring triangle numbers and asked to develop a formula to calculate the Nth triangle number. I'm sure we were guided towards the answer but I remember arriving at the visual solution quite independently. What previously seemed like random chaos, now had a pattern and order and a neat little formula describing it. Crucially though, I understood it. I experienced a genuine buzz.
That type of maths outside the classroom is way too difficult for me. I did however discover I have a knack for programming. Solving problems with logic and code is my happy place, it makes me laugh like a cartoon villain. Now I'm doing less coding at work, I really should do more of it at home, I should make it my hobby again.
The problem is one of motivation. While I have several coding projects I would like to start (or re-start), there is one idea that is consuming most of my thoughts. It's a huge, complicated and probably stupid idea that I don't really have the skills or time to complete. However every time I sit down to work on something else, it gets in the way.
I can't overstate the level of procrastination. The idea has been running around my head for over a decade now. I've spent entire evenings staring at the wall stuck in a mental loop. I have free time so I should start my project, but I've convinced myself I'll fail so why start. If I try to do something else I feel guilty for not at least trying to work on the project. I don't want to start, but I don't want to do anything else either. Before I know it, the whole evening is gone, it's time for bed and I've done nothing but brood.
It's unhealthy, it's getting worse and I need to break the cycle. Either dismiss the idea and move on or start the damned project.
I can't dismiss the idea because a tiny part of me thinks that it could be the best work I do and I need to find out if I'm up to the task. So I should start. And I should start by explaining what the idea is. For anyone who knows me, it won't be a surprise, I've been "joking" about the idea for years.
I've been using HCL Domino to develop applications since it was called Lotus Notes. Despite its bad reputation I think it's a solid development platform with excellent features, just wrapped in an ugly neglected shell. I don't understand why it has no real competitors, not ones with feature parity anyway. I'm constantly surprised by modern platforms that claim to be its equivalent, missing what makes Domino unique. I'm also frustrated with the direction that HCL seems to be going in with the development of the product, focusing on features that I don't use and ignoring problems that irritate me daily.
It's entirely possible I'm using Domino incorrectly, or simply using the wrong platform. But I can't seem to find one that meets my needs. Which brings me to the idea I can't seem to dismiss. I should build my own. How hard can it be?
Initially this will be the primary topic of this blog, an exportation of how I use Domino and what it would take to build a replacement suited to me. To be clear, this is a learning exercise. I've been thinking about the internals of something like Domino for a long time and I want to see and understand what makes it work. I am a realist, I don't expect to end up with a commercial product at the end, I'm making a toy I can play and experiment with. Ultimately I just want to code and this is the thing I want to code today.